













機(jī)器學(xué)習(xí)的方法
通過上節(jié)的介紹我們知曉了機(jī)器學(xué)習(xí)的大致范圍,那么機(jī)器學(xué)習(xí)里面究竟有多少經(jīng)典的算法呢?在這個(gè)部分我會(huì)簡(jiǎn)要介紹一下機(jī)器學(xué)習(xí)中的經(jīng)典代表方法。這部分介紹的重點(diǎn)是這些方法內(nèi)涵的思想,數(shù)學(xué)與實(shí)踐細(xì)節(jié)不會(huì)在這討論。
1、回歸算法
在大部分機(jī)器學(xué)習(xí)課程中,回歸算法都是介紹的***個(gè)算法。原因有兩個(gè):一.回歸算法比較簡(jiǎn)單,介紹它可以讓人平滑地從統(tǒng)計(jì)學(xué)遷移到機(jī)器學(xué)習(xí)中。二.回歸算法是后面若干強(qiáng)大算法的基石,如果不理解回歸算法,無法學(xué)習(xí)那些強(qiáng)大的算法。回歸算法有兩個(gè)重要的子類:即線性回歸和邏輯回歸。
線性回歸就是我們前面說過的房?jī)r(jià)求解問題。如何擬合出一條直線***匹配我所有的數(shù)據(jù)?一般使用“最小二乘法”來求解。“最小二乘法”的思想是這樣的,假設(shè)我們擬合出的直線代表數(shù)據(jù)的真實(shí)值,而觀測(cè)到的數(shù)據(jù)代表?yè)碛姓`差的值。為了盡可能減小誤差的影響,需要求解一條直線使所有誤差的平方和最小。最小二乘法將***問題轉(zhuǎn)化為求函數(shù)極值問題。函數(shù)極值在數(shù)學(xué)上我們一般會(huì)采用求導(dǎo)數(shù)為0的方法。但這種做法并不適合計(jì)算機(jī),可能求解不出來,也可能計(jì)算量太大。
計(jì)算機(jī)科學(xué)界專門有一個(gè)學(xué)科叫“數(shù)值計(jì)算”,專門用來提升計(jì)算機(jī)進(jìn)行各類計(jì)算時(shí)的準(zhǔn)確性和效率問題。例如,著名的“梯度下降”以及“牛頓法”就是數(shù)值計(jì)算中的經(jīng)典算法,也非常適合來處理求解函數(shù)極值的問題。梯度下降法是解決回歸模型中最簡(jiǎn)單且有效的方法之一。從嚴(yán)格意義上來說,由于后文中的神經(jīng)網(wǎng)絡(luò)和推薦算法中都有線性回歸的因子,因此梯度下降法在后面的算法實(shí)現(xiàn)中也有應(yīng)用。
邏輯回歸是一種與線性回歸非常類似的算法,但是,從本質(zhì)上講,線型回歸處理的問題類型與邏輯回歸不一致。線性回歸處理的是數(shù)值問題,也就是***預(yù)測(cè)出的結(jié)果是數(shù)字,例如房?jī)r(jià)。而邏輯回歸屬于分類算法,也就是說,邏輯回歸預(yù)測(cè)結(jié)果是離散的分類,例如判斷這封郵件是否是垃圾郵件,以及用戶是否會(huì)點(diǎn)擊此廣告等等。
實(shí)現(xiàn)方面的話,邏輯回歸只是對(duì)對(duì)線性回歸的計(jì)算結(jié)果加上了一個(gè)Sigmoid函數(shù),將數(shù)值結(jié)果轉(zhuǎn)化為了0到1之間的概率(Sigmoid函數(shù)的圖像一般來說并不直觀,你只需要理解對(duì)數(shù)值越大,函數(shù)越逼近1,數(shù)值越小,函數(shù)越逼近0),接著我們根據(jù)這個(gè)概率可以做預(yù)測(cè),例如概率大于0.5,則這封郵件就是垃圾郵件,或者腫瘤是否是惡性的等等。從直觀上來說,邏輯回歸是畫出了一條分類線,見下圖。
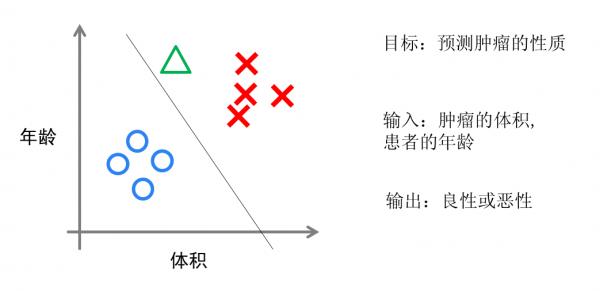
圖7 邏輯回歸的直觀解釋
假設(shè)我們有一組腫瘤患者的數(shù)據(jù),這些患者的腫瘤中有些是良性的(圖中的藍(lán)色點(diǎn)),有些是惡性的(圖中的紅色點(diǎn))。這里腫瘤的紅藍(lán)色可以被稱作數(shù)據(jù)的“標(biāo)簽”。同時(shí)每個(gè)數(shù)據(jù)包括兩個(gè)“特征”:患者的年齡與腫瘤的大小。我們將這兩個(gè)特征與標(biāo)簽映射到這個(gè)二維空間上,形成了我上圖的數(shù)據(jù)。
當(dāng)我有一個(gè)綠色的點(diǎn)時(shí),我該判斷這個(gè)腫瘤是惡性的還是良性的呢?根據(jù)紅藍(lán)點(diǎn)我們訓(xùn)練出了一個(gè)邏輯回歸模型,也就是圖中的分類線。這時(shí),根據(jù)綠點(diǎn)出現(xiàn)在分類線的左側(cè),因此我們判斷它的標(biāo)簽應(yīng)該是紅色,也就是說屬于惡性腫瘤。
邏輯回歸算法劃出的分類線基本都是線性的(也有劃出非線性分類線的邏輯回歸,不過那樣的模型在處理數(shù)據(jù)量較大的時(shí)候效率會(huì)很低),這意味著當(dāng)兩類之間的界線不是線性時(shí),邏輯回歸的表達(dá)能力就不足。下面的兩個(gè)算法是機(jī)器學(xué)習(xí)界***大且重要的算法,都可以擬合出非線性的分類線。
2、神經(jīng)網(wǎng)絡(luò)
神經(jīng)網(wǎng)絡(luò)(也稱之為人工神經(jīng)網(wǎng)絡(luò),ANN)算法是80年代機(jī)器學(xué)習(xí)界非常流行的算法,不過在90年代中途衰落。現(xiàn)在,攜著“深度學(xué)習(xí)”之勢(shì),神經(jīng)網(wǎng)絡(luò)重裝歸來,重新成為***大的機(jī)器學(xué)習(xí)算法之一。
神經(jīng)網(wǎng)絡(luò)的誕生起源于對(duì)大腦工作機(jī)理的研究。早期生物界學(xué)者們使用神經(jīng)網(wǎng)絡(luò)來模擬大腦。機(jī)器學(xué)習(xí)的學(xué)者們使用神經(jīng)網(wǎng)絡(luò)進(jìn)行機(jī)器學(xué)習(xí)的實(shí)驗(yàn),發(fā)現(xiàn)在視覺與語(yǔ)音的識(shí)別上效果都相當(dāng)好。在BP算法(加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程的數(shù)值算法)誕生以后,神經(jīng)網(wǎng)絡(luò)的發(fā)展進(jìn)入了一個(gè)熱潮。BP算法的發(fā)明人之一是前面介紹的機(jī)器學(xué)習(xí)大牛Geoffrey Hinton(圖1中的中間者)。
具體說來,神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)機(jī)理是什么?簡(jiǎn)單來說,就是分解與整合。在著名的Hubel-Wiesel試驗(yàn)中,學(xué)者們研究貓的視覺分析機(jī)理是這樣的。
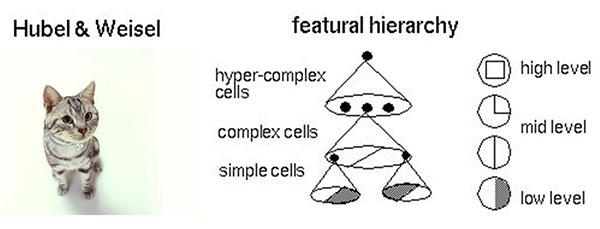
圖8 Hubel-Wiesel試驗(yàn)與大腦視覺機(jī)理
比方說,一個(gè)正方形,分解為四個(gè)折線進(jìn)入視覺處理的下一層中。四個(gè)神經(jīng)元分別處理一個(gè)折線。每個(gè)折線再繼續(xù)被分解為兩條直線,每條直線再被分解為黑白兩個(gè)面。于是,一個(gè)復(fù)雜的圖像變成了大量的細(xì)節(jié)進(jìn)入神經(jīng)元,神經(jīng)元處理以后再進(jìn)行整合,***得出了看到的是正方形的結(jié)論。這就是大腦視覺識(shí)別的機(jī)理,也是神經(jīng)網(wǎng)絡(luò)工作的機(jī)理。
讓我們看一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)的邏輯架構(gòu)。在這個(gè)網(wǎng)絡(luò)中,分成輸入層,隱藏層,和輸出層。輸入層負(fù)責(zé)接收信號(hào),隱藏層負(fù)責(zé)對(duì)數(shù)據(jù)的分解與處理,***的結(jié)果被整合到輸出層。每層中的一個(gè)圓代表一個(gè)處理單元,可以認(rèn)為是模擬了一個(gè)神經(jīng)元,若干個(gè)處理單元組成了一個(gè)層,若干個(gè)層再組成了一個(gè)網(wǎng)絡(luò),也就是”神經(jīng)網(wǎng)絡(luò)”。
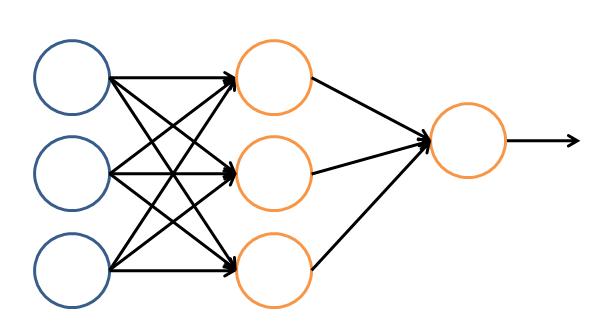
圖9 神經(jīng)網(wǎng)絡(luò)的邏輯架構(gòu)
在神經(jīng)網(wǎng)絡(luò)中,每個(gè)處理單元事實(shí)上就是一個(gè)邏輯回歸模型,邏輯回歸模型接收上層的輸入,把模型的預(yù)測(cè)結(jié)果作為輸出傳輸?shù)较乱粋€(gè)層次。通過這樣的過程,神經(jīng)網(wǎng)絡(luò)可以完成非常復(fù)雜的非線性分類。
下圖會(huì)演示神經(jīng)網(wǎng)絡(luò)在圖像識(shí)別領(lǐng)域的一個(gè)著名應(yīng)用,這個(gè)程序叫做LeNet,是一個(gè)基于多個(gè)隱層構(gòu)建的神經(jīng)網(wǎng)絡(luò)。通過LeNet可以識(shí)別多種手寫數(shù)字,并且達(dá)到很高的識(shí)別精度與擁有較好的魯棒性。
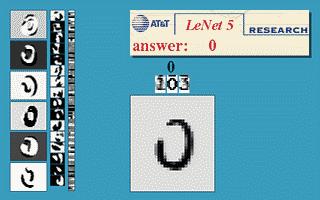
圖10 LeNet的效果展示
右下方的方形中顯示的是輸入計(jì)算機(jī)的圖像,方形上方的紅色字樣“answer”后面顯示的是計(jì)算機(jī)的輸出。左邊的三條豎直的圖像列顯示的是神經(jīng)網(wǎng)絡(luò)中三個(gè)隱藏層的輸出,可以看出,隨著層次的不斷深入,越深的層次處理的細(xì)節(jié)越低,例如層3基本處理的都已經(jīng)是線的細(xì)節(jié)了。LeNet的發(fā)明人就是前文介紹過的機(jī)器學(xué)習(xí)的大牛Yann LeCun(圖1右者)。
進(jìn)入90年代,神經(jīng)網(wǎng)絡(luò)的發(fā)展進(jìn)入了一個(gè)瓶頸期。其主要原因是盡管有BP算法的加速,神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程仍然很困難。因此90年代后期支持向量機(jī)(SVM)算法取代了神經(jīng)網(wǎng)絡(luò)的地位。
3、SVM(支持向量機(jī))
支持向量機(jī)算法是誕生于統(tǒng)計(jì)學(xué)習(xí)界,同時(shí)在機(jī)器學(xué)習(xí)界大放光彩的經(jīng)典算法。
支持向量機(jī)算法從某種意義上來說是邏輯回歸算法的強(qiáng)化:通過給予邏輯回歸算法更嚴(yán)格的優(yōu)化條件,支持向量機(jī)算法可以獲得比邏輯回歸更好的分類界線。但是如果沒有某類函數(shù)技術(shù),則支持向量機(jī)算法最多算是一種更好的線性分類技術(shù)。
但是,通過跟高斯“核”的結(jié)合,支持向量機(jī)可以表達(dá)出非常復(fù)雜的分類界線,從而達(dá)成很好的的分類效果。“核”事實(shí)上就是一種特殊的函數(shù),最典型的特征就是可以將低維的空間映射到高維的空間。
例如下圖所示:

圖11 支持向量機(jī)圖例
我們?nèi)绾卧诙S平面劃分出一個(gè)圓形的分類界線?在二維平面可能會(huì)很困難,但是通過“核”可以將二維空間映射到三維空間,然后使用一個(gè)線性平面就可以達(dá)成類似效果。也就是說,二維平面劃分出的非線性分類界線可以等價(jià)于三維平面的線性分類界線。于是,我們可以通過在三維空間中進(jìn)行簡(jiǎn)單的線性劃分就可以達(dá)到在二維平面中的非線性劃分效果。
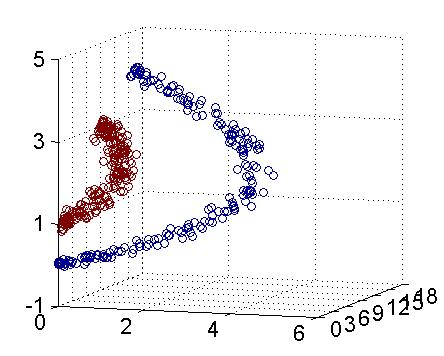
圖12 三維空間的切割
支持向量機(jī)是一種數(shù)學(xué)成分很濃的機(jī)器學(xué)習(xí)算法(相對(duì)的,神經(jīng)網(wǎng)絡(luò)則有生物科學(xué)成分)。在算法的核心步驟中,有一步證明,即將數(shù)據(jù)從低維映射到高維不會(huì)帶來***計(jì)算復(fù)雜性的提升。于是,通過支持向量機(jī)算法,既可以保持計(jì)算效率,又可以獲得非常好的分類效果。因此支持向量機(jī)在90年代后期一直占據(jù)著機(jī)器學(xué)習(xí)中最核心的地位,基本取代了神經(jīng)網(wǎng)絡(luò)算法。直到現(xiàn)在神經(jīng)網(wǎng)絡(luò)借著深度學(xué)習(xí)重新興起,兩者之間才又發(fā)生了微妙的平衡轉(zhuǎn)變。
4、聚類算法
前面的算法中的一個(gè)顯著特征就是我的訓(xùn)練數(shù)據(jù)中包含了標(biāo)簽,訓(xùn)練出的模型可以對(duì)其他未知數(shù)據(jù)預(yù)測(cè)標(biāo)簽。在下面的算法中,訓(xùn)練數(shù)據(jù)都是不含標(biāo)簽的,而算法的目的則是通過訓(xùn)練,推測(cè)出這些數(shù)據(jù)的標(biāo)簽。這類算法有一個(gè)統(tǒng)稱,即無監(jiān)督算法(前面有標(biāo)簽的數(shù)據(jù)的算法則是有監(jiān)督算法)。無監(jiān)督算法中最典型的代表就是聚類算法。
讓我們還是拿一個(gè)二維的數(shù)據(jù)來說,某一個(gè)數(shù)據(jù)包含兩個(gè)特征。我希望通過聚類算法,給他們中不同的種類打上標(biāo)簽,我該怎么做呢?簡(jiǎn)單來說,聚類算法就是計(jì)算種群中的距離,根據(jù)距離的遠(yuǎn)近將數(shù)據(jù)劃分為多個(gè)族群。
聚類算法中最典型的代表就是K-Means算法。
5、降維算法
降維算法也是一種無監(jiān)督學(xué)習(xí)算法,其主要特征是將數(shù)據(jù)從高維降低到低維層次。在這里,維度其實(shí)表示的是數(shù)據(jù)的特征量的大小,例如,房?jī)r(jià)包含房子的長(zhǎng)、寬、面積與房間數(shù)量四個(gè)特征,也就是維度為4維的數(shù)據(jù)。可以看出來,長(zhǎng)與寬事實(shí)上與面積表示的信息重疊了,例如面積=長(zhǎng) × 寬。通過降維算法我們就可以去除冗余信息,將特征減少為面積與房間數(shù)量?jī)蓚€(gè)特征,即從4維的數(shù)據(jù)壓縮到2維。于是我們將數(shù)據(jù)從高維降低到低維,不僅利于表示,同時(shí)在計(jì)算上也能帶來加速。
剛才說的降維過程中減少的維度屬于肉眼可視的層次,同時(shí)壓縮也不會(huì)帶來信息的損失(因?yàn)樾畔⑷哂嗔?。如果肉眼不可視,或者沒有冗余的特征,降維算法也能工作,不過這樣會(huì)帶來一些信息的損失。但是,降維算法可以從數(shù)學(xué)上證明,從高維壓縮到的低維中***程度地保留了數(shù)據(jù)的信息。因此,使用降維算法仍然有很多的好處。
降維算法的主要作用是壓縮數(shù)據(jù)與提升機(jī)器學(xué)習(xí)其他算法的效率。通過降維算法,可以將具有幾千個(gè)特征的數(shù)據(jù)壓縮至若干個(gè)特征。另外,降維算法的另一個(gè)好處是數(shù)據(jù)的可視化,例如將5維的數(shù)據(jù)壓縮至2維,然后可以用二維平面來可視。降維算法的主要代表是PCA算法(即主成分分析算法)。
6、推薦算法
推薦算法是目前業(yè)界非常火的一種算法,在電商界,如亞馬遜,天貓,京東等得到了廣泛的運(yùn)用。推薦算法的主要特征就是可以自動(dòng)向用戶推薦他們最感興趣的東西,從而增加購(gòu)買率,提升效益。推薦算法有兩個(gè)主要的類別:
一類是基于物品內(nèi)容的推薦,是將與用戶購(gòu)買的內(nèi)容近似的物品推薦給用戶,這樣的前提是每個(gè)物品都得有若干個(gè)標(biāo)簽,因此才可以找出與用戶購(gòu)買物品類似的物品,這樣推薦的好處是關(guān)聯(lián)程度較大,但是由于每個(gè)物品都需要貼標(biāo)簽,因此工作量較大。
另一類是基于用戶相似度的推薦,則是將與目標(biāo)用戶興趣相同的其他用戶購(gòu)買的東西推薦給目標(biāo)用戶,例如小A歷史上買了物品B和C,經(jīng)過算法分析,發(fā)現(xiàn)另一個(gè)與小A近似的用戶小D購(gòu)買了物品E,于是將物品E推薦給小A。
兩類推薦都有各自的優(yōu)缺點(diǎn),在一般的電商應(yīng)用中,一般是兩類混合使用。推薦算法中最有名的算法就是協(xié)同過濾算法。
7、其他
除了以上算法之外,機(jī)器學(xué)習(xí)界還有其他的如高斯判別,樸素貝葉斯,決策樹等等算法。但是上面列的六個(gè)算法是使用最多,影響最廣,種類最全的典型。機(jī)器學(xué)習(xí)界的一個(gè)特色就是算法眾多,發(fā)展百花齊放。
下面做一個(gè)總結(jié),按照訓(xùn)練的數(shù)據(jù)有無標(biāo)簽,可以將上面算法分為監(jiān)督學(xué)習(xí)算法和無監(jiān)督學(xué)習(xí)算法,但推薦算法較為特殊,既不屬于監(jiān)督學(xué)習(xí),也不屬于非監(jiān)督學(xué)習(xí),是單獨(dú)的一類。




















