理解深度學習的鑰匙–參數篇
這是你所有看到的有關神經網絡參數的理解中最通俗易懂的一個了,公式也減到了最少,神經網絡的專業人士繞道哦。
在上一篇《理解深度學習的鑰匙 –啟蒙篇》,我們提到定義⼀個二次代價函數,也叫損失函數或目標函數:
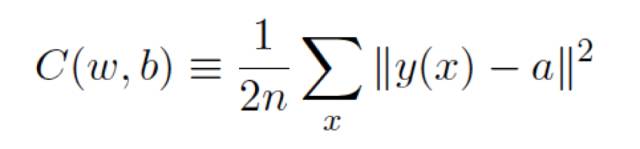
這⾥ w 表⽰所有的⽹絡中權重的集合,b 是所有的偏置,n 是訓練輸⼊數據的個數,a 是表⽰當輸⼊為 x 時輸出的向量,y(x)是實際輸出的向量,求和則是在總的訓練輸⼊ x 上進⾏的。
參考《理解深度學習的鑰匙 –啟蒙篇》文章C(v)中v的計算過程,∇C 來表示梯度向量:
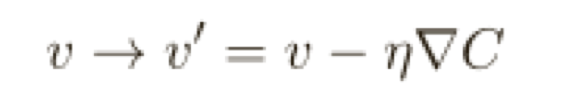
現在有兩個分量組成w 和b,⽽梯度向量∇C 則有相應的分量∂C/∂w 和 ∂C/∂b,⽤這些分量來寫梯度下降的更新規則,我們得到:
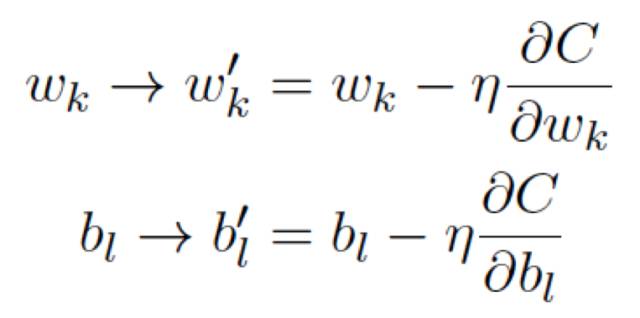
通過重復應⽤這⼀更新規則我們就能“讓球體滾下⼭”,并且有望能找到代價函數的最⼩值,換句話說,這是⼀個能讓神經⽹絡學習的規則。
注意這個代價函數是遍及每個訓練樣本的,x表示某一個樣本:
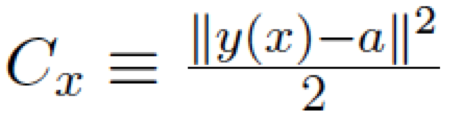
在實踐中,為了計算梯度∇C,我們需要為每個訓練輸⼊x 單獨地計算梯度值∇Cx,然后求平均值:
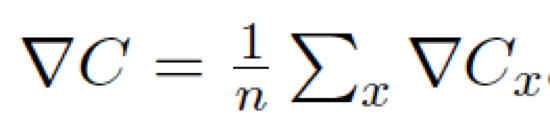
不幸的是,當訓練輸⼊的數量過⼤時會花費很⻓時間,這樣會使學習變得相當緩慢。
1、隨機梯度下降
這一節你將了解具體的一個訓練過程,了解什么叫作⼩批量數據(mini-batch),什么叫作訓練迭代期(epoch)。
有種叫做隨機梯度下降的算法能夠加速學習,其思想就是通過隨機選取⼩量訓練輸⼊樣本來計算∇Cx,進⽽估算梯度∇C,通過計算少量樣本的平均值我們可以快速得到⼀個對于實際梯度∇C 的很好的估算,這有助于加速梯度下降,進⽽加速學習過程。
更準確地說,隨機梯度下降通過隨機選取⼩量的m 個訓練輸⼊來⼯作,我們將這些隨機的訓練輸⼊標記為X1;X2… Xm,并把它們稱為⼀個⼩批量數據(mini-batch)。假設樣本數量m ⾜夠⼤,我們期望∇Cxj 的平均值⼤致相等于整個∇Cx 的平均值,即:
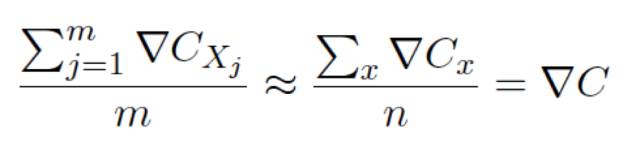
可以推導得到:
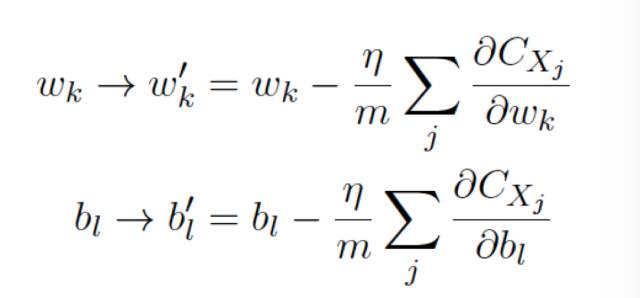
然后我們再挑選另⼀隨機選定的⼩批量數據去訓練,直到我們⽤完了所有的訓練輸⼊,這被稱為完成了⼀個訓練迭代期(epoch)。然后我們就會開始⼀個新的訓練迭代期。
我們可以把隨機梯度下降想象成⼀次⺠意調查:在⼀個⼩批量數據上采樣⽐對⼀個完整數據集進⾏梯度下降分析要容易得多,正如進⾏⼀次⺠意調查⽐舉⾏⼀次全⺠選舉要更容易。例如,如果我們有⼀個規模為n = 60000 的訓練集,就像MNIST,并選取⼩批量數據⼤⼩為m=10,這意味著在估算梯度過程中加速了6000 倍。
現在讓我們寫⼀個學習如何識別⼿寫數字的程序,使⽤隨機梯度下降算法和MNIST
訓練數據,除了MNIST 數據,我們還需要⼀個叫做Numpy 的Python 庫,⽤來做快速線性代數,不要怕,筆者不會貼代碼,只是示意一下,大家理解函數調用的方式即可:
在加載完MNIST 數據之后,我們將設置⼀個有784個像素輸入、30 個隱藏層神經元、10個輸出的Network:

我們將使⽤隨機梯度下降來從MNIST training_data 學習超過30 次迭代期,⼩批量數據⼤⼩為10,學習速率η=3.0:
![]()
打印內容顯⽰了在每輪訓練期后神經⽹絡能正確識別測試圖像的數量。正如你所⻅到,在僅僅⼀次迭代期后,達到了10,000 中選中的9,129 個,⽽且數⽬還在持續增⻓,經過訓練的⽹絡給出的識別率約為95%:

讓我們重新運⾏上⾯的實驗,將隱藏神經元數量改到100:
![]()
果然,它將結果提升⾄96.59%,⾄少在這種情況下,使⽤更多的隱藏神經元幫助我們得到了更好的結果。
當然,為了獲得這些準確性,我不得不對訓練的迭代期數量(epoch),⼩批量數據⼤⼩(minbatch)和學習速率η做特別的選擇,正如我上⾯所提到的,這些在我們的神經⽹絡中被稱為超參數,以區別于通過我們的學習算法所學到的參數(權重和偏置),如果我們選擇了糟糕的超參數,我們會得到較差的結果。
假如我們選定學習速率為η= 0.001:
![]()
結果則不太令人鼓舞了:

然⽽,你可以看到⽹絡的性能隨著時間的推移慢慢地變好了,這表明應該增⼤學習速率,例如η= 0.01,如果我們那樣做了,我們會得到更好的結果,這表明我們應該再次增加學習速率。(如果改變能夠改善⼀些事情,試著做更多!)如果我們這樣做⼏次,我們最終會得到⼀個像η=1.0 的學習速率(或者調整到3.0),這跟我們之前的實驗很接近。因此即使我們最初選擇了糟糕的超參數,我們⾄少獲得了⾜夠的信息來幫助我們改善對于超參數的選擇。
通常,調試⼀個神經⽹絡是具有挑戰性的,尤其是當初始的超參數的選擇產⽣的結果還不如隨機噪點的時候。假如我們試⽤之前成功的具有30 個隱藏神經元的⽹絡結構,但是學習速率改為η= 100,在這點上,我們實際⾛的太遠,學習速率太⾼了:

我們可能不僅關⼼學習速率,還要關⼼我們的神經⽹絡中的其它每⼀個部分,我們可能想知道是否⽤了讓⽹絡很難學習的初始權重和偏置?或者可能我們沒有⾜夠的訓練數據來獲得有意義的學習?或者我們沒有進⾏⾜夠的迭代期?或者可能對于具有這種結構的神經⽹絡,學習識別⼿寫數字是不可能的?可能學習速率太低?或者可能學習速率太⾼?當你第⼀次遇到問題,你不總是能有把握。
就像常規編程那樣,它是⼀⻔藝術,你需要學習調試的藝術來獲得神經⽹絡更好的結果,更普通的是,我們需要啟發式⽅法來選擇好的超參數和好的結構,后面將討論怎么樣選擇超參數。
2、邁向深度學習
這一節你將了解神經網絡是如何過渡到深度學習的。
雖然我們的神經網絡給出了令⼈印象深刻的表現,但這樣的表現帶有⼏分神秘,⽹絡中的權重和偏置是被⾃動發現的,這意味著我們不能⽴即解釋⽹絡怎么做的、做了什么,我們能否找到⼀些方法來理解我們的⽹絡通過什么原理分類⼿寫數字?并且,在知道了這些原理后,我們能做得更好嗎?
為了讓這些問題更具體,我們假設數⼗年后神經⽹絡引發了⼈工智能(AI)。到那個時候,我們能明⽩這種智能⽹絡的⼯作機制嗎?或許,因為有著⾃動學習得到的權重和偏置,這些是我們⽆法理解的,這樣的神經⽹絡對我們來說是不透明的。在⼈⼯智能的早期研究階段,⼈們希望在構建⼈⼯智能的努⼒過程中,也同時能夠幫助我們理解智能背后的機制,以及⼈類⼤腦的運轉⽅式,但結果可能是我們既不能夠理解⼤腦的機制,也不能夠理解⼈⼯智能的機制。
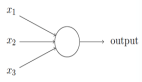
為解決這些問題,讓我們重新思考⼀下我在本章開始時所給的⼈⼯神經元的解釋,作為⼀種衡量證據的方法,假設我們要確定⼀幅圖像是否顯⽰有⼈臉 :
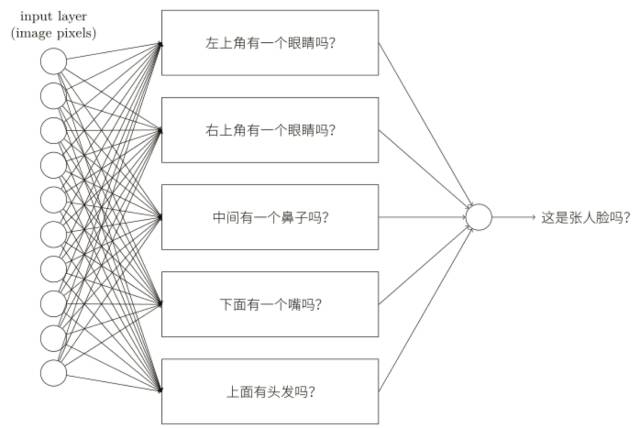
我們可以用解決⼿寫識別問題的相同⽅式來攻克這個問題 —— ⽹絡的輸⼊是圖像中的像素,⽹絡的輸出是⼀個單個的神經元⽤于表明“是的,這是⼀張臉”或“不,這不是⼀張臉”,假設我們就采取了這個⽅法,但接下來我們先不去使⽤⼀個學習算法,⽽是去嘗試親⼿設計⼀個⽹絡,并為它選擇合適的權重和偏置。我們要怎樣做呢?暫時先忘掉神經⽹絡,我們受到啟發的⼀個想法是將這個問題分解成⼦問題:圖像的左上⻆有⼀個眼睛嗎?右上⻆有⼀個眼睛嗎?中間有⼀個⿐⼦嗎?下⾯中央有⼀個嘴嗎?上⾯有頭發嗎?諸如此類,如果⼀些問題的回答是“是”,或者甚⾄僅僅是“可能是”,那么我們可以作出結論這個圖像可能是⼀張臉,相反地,如果⼤多數這些問題的答案是“不是”,那么這張圖像可能不是⼀張臉。
這個想法表明了如果我們能夠使用神經⽹絡來解決這些⼦問題,那么我們也許可以通過將這些解決⼦問題的⽹絡結合起來,構成⼀個⼈臉檢測的神經⽹絡,下圖是⼀個可能的結構,其中的⽅框表⽰⼦⽹絡,注意,這不是⼀個⼈臉檢測問題的現實的解決⽅法,⽽是為了幫助我們構建起⽹絡如何運轉的直觀感受。
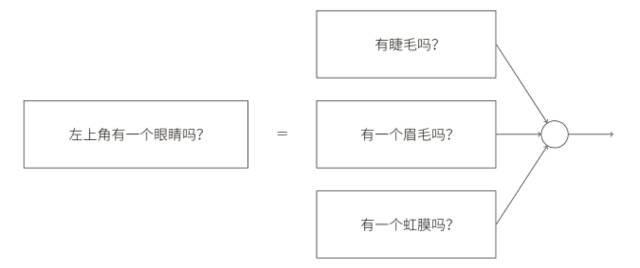
子網絡也可以被繼續分解,這看上去很合理,假設我們考慮這個問題:“左上⻆有⼀個眼睛嗎?”這個問題可以被分解成這些⼦問題:“有⼀個眉⽑嗎?”,“有睫⽑嗎?”,“有虹膜嗎?”等等,當然這些問題也應該包含關于位置的信息 —— 諸如“在左上⻆有眉⽑,上⾯有虹膜嗎?”——但是讓我們先保持簡單,回答問題“左上⻆有⼀個眼睛嗎?”的⽹絡能夠被分解成:
這些子問題也同樣可以繼續被分解,并通過多個⽹絡層傳遞得越來越遠,最終,我們的⼦⽹絡可以回答那些只包含若⼲個像素點的簡單問題。舉例來說,這些簡單的問題可能是詢問圖像中的⼏個像素是否構成⾮常簡單的形狀,這些問題就可以被那些與圖像中原始像素點相連的單個神經元所回答,最終的結果是,我們設計出了⼀個⽹絡,它將⼀個⾮常復雜的問題 —— 這張圖像是否有⼀張⼈臉 —— 分解成在單像素層⾯上就可回答的⾮常簡單的問題,它通過⼀系列多層結構來完成,在前⾯的⽹絡層,它回答關于輸⼊圖像⾮常簡單明確的問題,在后⾯的⽹絡層,它建⽴了⼀個更加復雜和抽象的層級結構,包含這種多層結構 —— 兩層或更多隱藏層 —— 的⽹絡被稱為深度神經網絡。
⾃ 2006 年以來,⼈們已經開發了⼀系列技術使深度神經網絡能夠學習,這些深度學習技術基于隨機梯度下降和反向傳播,并引進了新的想法,這些技術已經使更深(更⼤)的⽹絡能夠被訓練 —— 現在訓練⼀個有 5 到 10 層隱藏層的⽹絡都是很常⻅的,⽽且事實證明,在許多問題上,它們⽐那些淺層神經⽹絡,例如僅有⼀個隱藏層的⽹絡,表現的更加出⾊,當然,原因是深度⽹絡能夠構建起⼀個復雜的概念的層次結構。
3、交叉熵代價函數
這一節你將了解神經網絡訓練速度太慢的原因,為什么要用交叉熵代價函數替代MSE或二次代價函數。
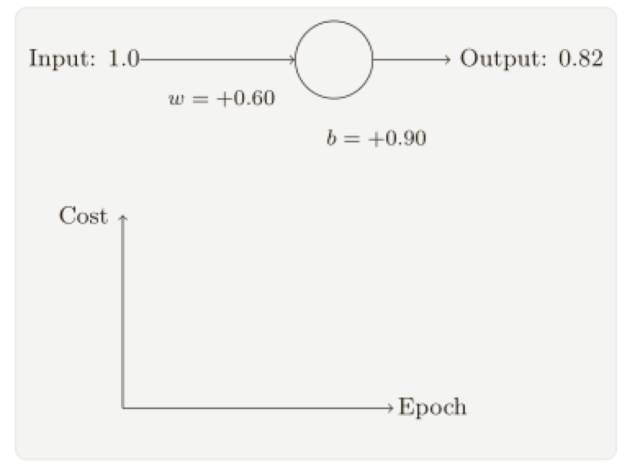
我們希望和期待神經網絡可以從錯誤中快速地學習,在實踐中,這種情況經常出現嗎?為了回答這個問題,讓我們看看⼀個⼩例⼦,這個例⼦包含⼀個只有⼀個輸入的神經元:

我們會訓練這個神經元來做⼀件非常簡單的事:讓輸⼊ 1 轉化為 0。當然,這很簡單了,⼿⼯找到合適的權重和偏置就可以了,然⽽,看起來使⽤梯度下降的⽅式來學習權重和偏置是很有啟發的,所以,我們來看看神經元如何學習。
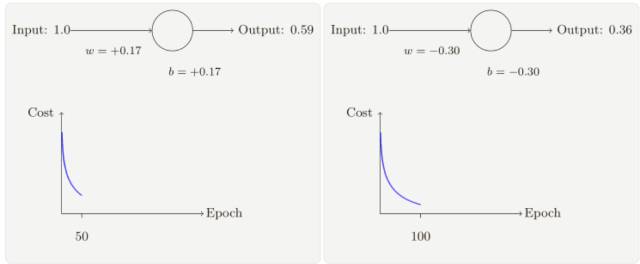
為了讓這個例⼦更明確,我會⾸先將權重和偏置初始化為 0.6 和 0.9。這些就是⼀般的開始學習的選擇,并沒有任何刻意的想法。⼀開始的神經元的輸出是 0.82,所以這離我們的⽬標輸出0.0 還差得很遠,從下圖來看看神經元如何學習到讓輸出接近 0.0 的,注意這些圖像實際上是正在進⾏梯度的計算,然后使⽤梯度更新來對權重和偏置進⾏更新,并且展⽰結果,設置學習速率 η = 0.15 進行學習⼀⽅⾯⾜夠慢的讓我們跟隨學習的過程,另⼀⽅⾯也保證了學習的時間不會太久,⼏秒鐘應該就⾜夠了,代價函數就是MSE,C。
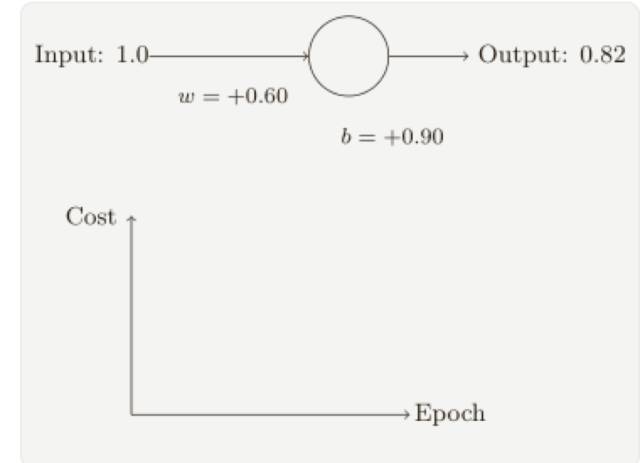
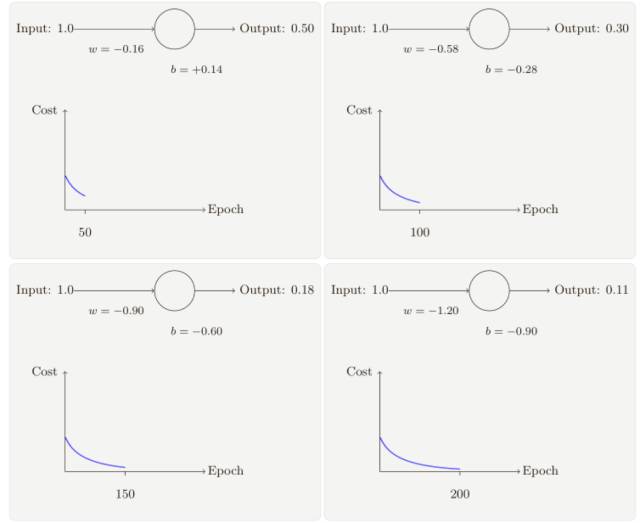
隨著迭代期的增加,神經元的輸出、權重、偏置和代價的變化如下⾯⼀系列圖形所⽰:
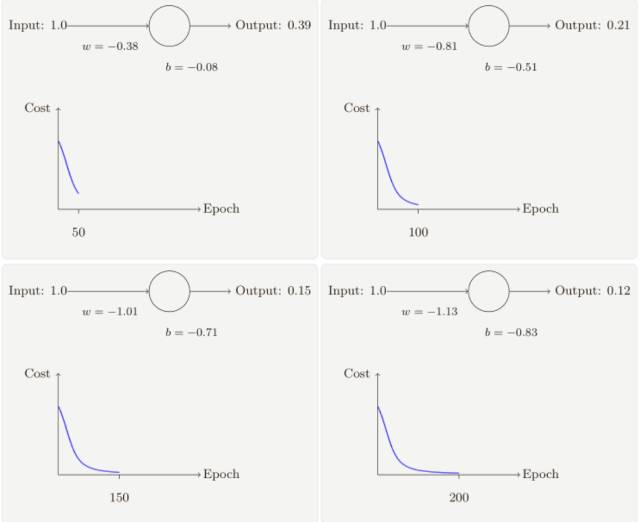
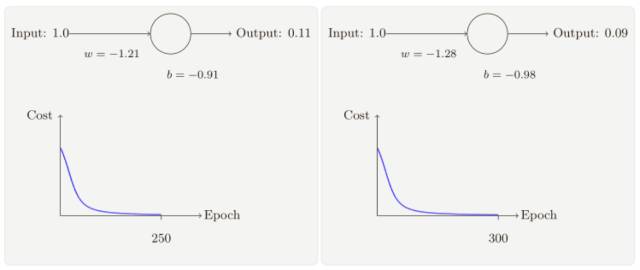
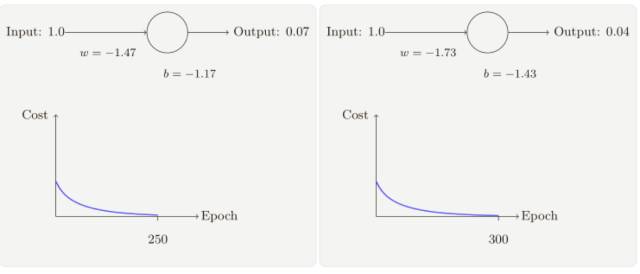
正如你所⻅,神經元快速地學到了使得代價函數下降的權重和偏置,給出了最終的輸出為0.09,這雖然不是我們的目標輸出 0.0,但是已經挺好了。
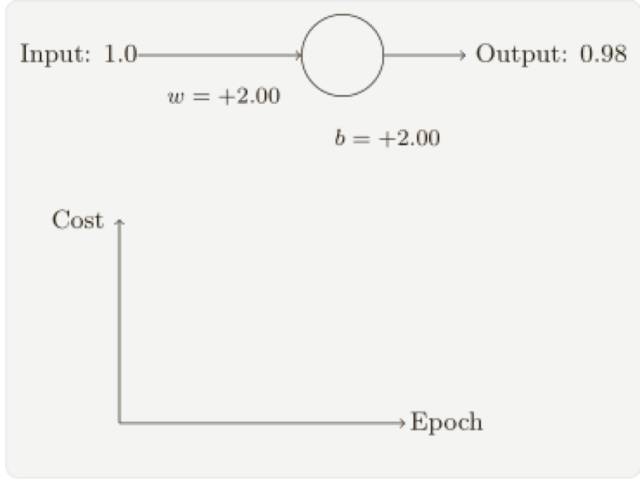
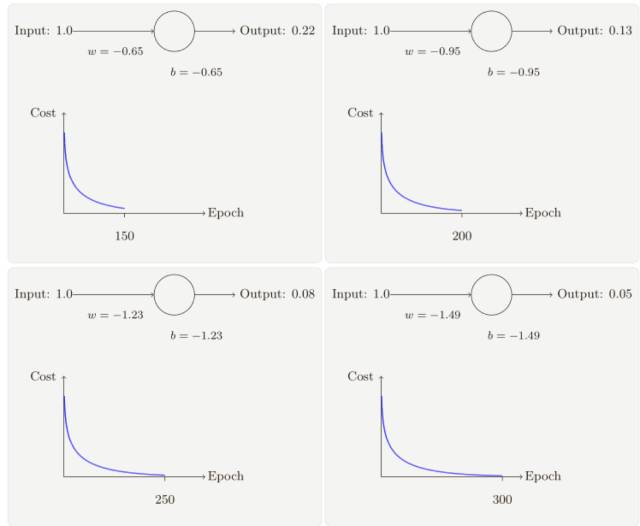
假設我們現在將初始權重和偏置都設置為 2.0,此時初始輸出為 0.98,這是和目標值的差距相當⼤的,現在看看神經元學習的過程。
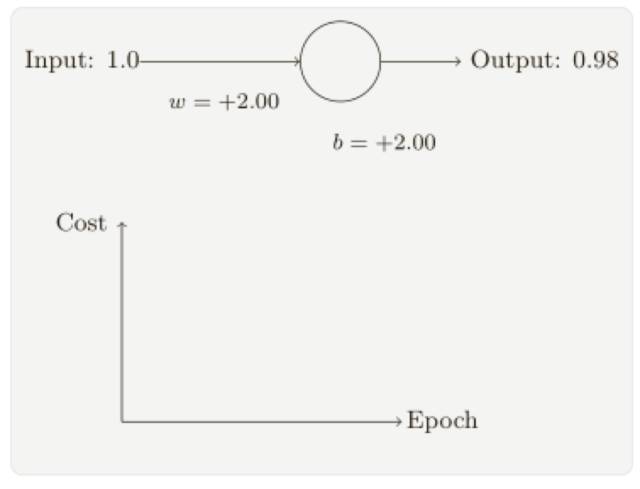
你將看到如下的⼀系列變化:
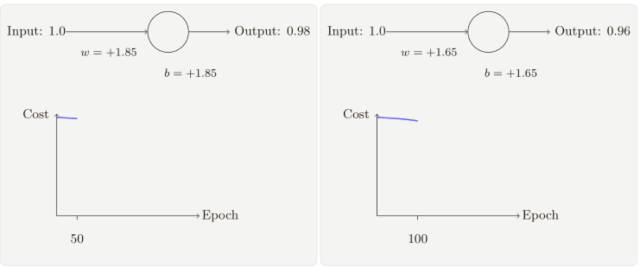
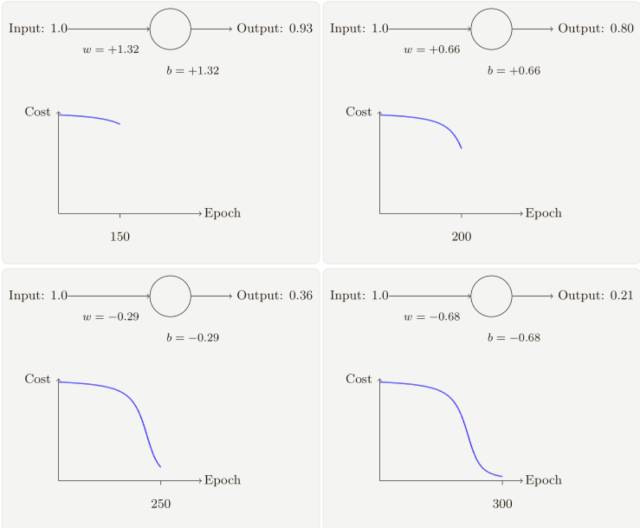
雖然這個例⼦使用了同樣的學習速率(η = 0.15),我們可以看到剛開始的學習速度是⽐較緩慢的,對前 150 左右的學習次數,權重和偏置并沒有發⽣太⼤的變化,隨后學習速度加快,與上⼀個例⼦中類似了,神經⽹絡的輸出也迅速接近 0.0。
這種行為看起來和⼈類學習⾏為差異很,我們通常是在犯錯⽐較明顯的時候學習的速度最快,但是我們已經看到了⼈⼯神經元在其犯錯較⼤的情況下其實學習很有難度,⽽且,這種現象不僅僅是在這個⼩例⼦中出現,也會在更加⼀般的神經⽹絡中出現,為何學習如此緩慢?我們能夠找到避免這種情況的方法嗎?
為了理解這個問題的源頭,想想我們的神經元是通過改變權重和偏置,并以⼀個代價函數的偏導數(∂C/∂w 和 ∂C/∂b)決定的速度學習,所以,我們在說“學習緩慢”時,實際上就是說這些偏導數很⼩,理解他們為何這么⼩就是我們⾯臨的挑戰,為了理解這些,讓我們計算偏導數看看,我們⼀直在⽤的是⼆次代價函數,定義如下:
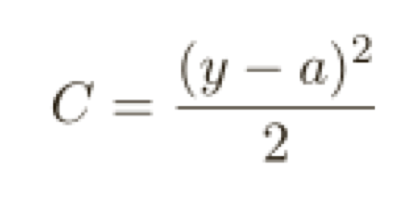
其中 a 是神經元的輸出,訓練輸⼊為 x = 1,y = 0 則是⽬標輸出,顯式地使⽤權重和偏置來表達這個,我們有 a = σ(z),其中 z = wx + b,使用鏈式法則來求權重和偏置的偏導數就有:
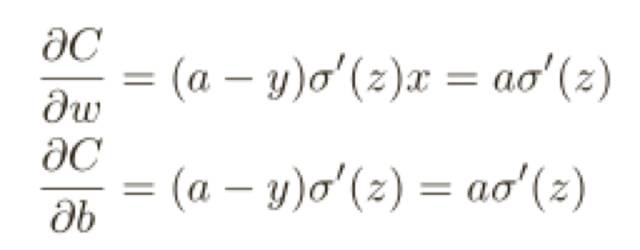
其中我已經將 x = 1 和 y = 0 代⼊了。為了理解這些表達式的行為,讓我們仔細看 σ ′ (z) 這⼀項,⾸先回憶⼀下 σ 函數圖像:
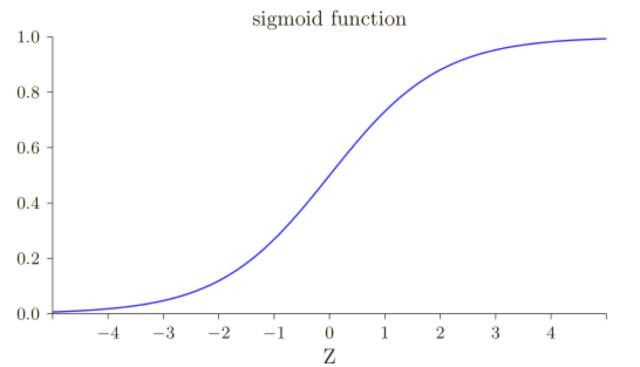
我們可以從這幅圖看出,當神經元的輸出接近 1 的時候,曲線變得相當平,所以 σ ′ (z) 就很⼩了,也即∂C/∂w 和 ∂C/∂b 會⾮常⼩,這其實就是學習緩慢的原因所在,⽽且,我們后面也會提到,這種學習速度下降的原因實際上也是更加⼀般的神經⽹絡學習緩慢的原因,并不僅僅是在這個特例中特有的。
研究表明,我們可以通過使用交叉熵代價函數來替換⼆次代價函數,為了理解什么是交叉熵,我們稍微改變⼀下之前的簡單例⼦,假設,我們現在要訓練⼀個包含若⼲輸⼊變量的的神經元,x1 ,x2 ,... 對應的權重為 w1 ,w2 ,... 和偏置 b:
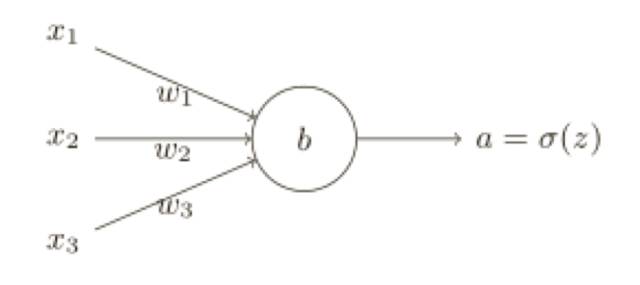
神經元的輸出就是 a = σ(z),其中 z =∑j W j X j+ b 是輸⼊的帶權和,我們如下定義這個神經元的交叉熵代價函數:
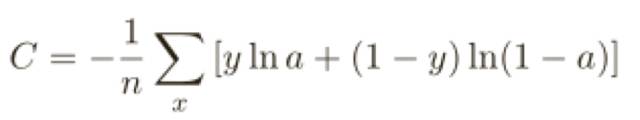
其中 n 是訓練數據的總數,求和是在所有的訓練輸⼊ x 上進⾏的,y 是對應的⽬標輸出,在解決學習緩慢前,我們來看看交叉熵為何能夠解釋成⼀個代價函數。
如果對于所有的訓練輸⼊ x,神經元實際的輸出接近⽬標值,那么交叉熵將接近 0,假設在這個例⼦中,y = 0 ⽽ a ≈ 0,交叉熵接近于0,反之,y = 1 ⽽ a ≈ 1,交叉熵也接近于0,綜上所述,交叉熵是⾮負的,在神經元達到很好的正確率的時候會接近 0,這些其實就是我們想要的代價函數的特性,其實這些特性也是⼆次代價函數具備的,所以,交叉熵就是很好的選擇了。
但是交叉熵代價函數有⼀個⽐二次代價函數更好的特性就是它避免了學習速度下降的問題,為了弄清楚這個情況,我們來算算交叉熵函數關于權重的偏導數,只列出結果:
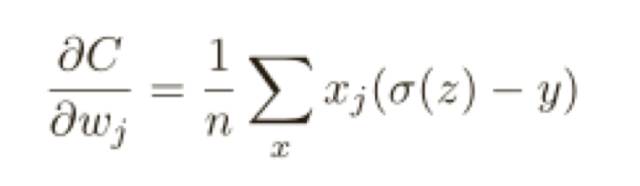
這是⼀個優美的公式,它告訴我們權重學習的速度受到 σ(z) − y,也就是輸出中的誤差的控制,更大的誤差,更快的學習速度,這是我們直覺上期待的結果。特別地,這個代價函數還避免了像在⼆次代價函數中類似⽅程中 σ ′ (z) 導致的學習緩慢。
讓我們重回最原初的例⼦,來看看換成了交叉熵之后的學習過程,現在仍然按照前⾯的參數配置來初始化⽹絡,開始權重為 0.6,而偏置為 0.9。
看看在換成交叉熵之后⽹絡的學習情況,你將看到如下變化的曲線:
毫不奇怪,在這個例子中,神經元學習得相當出⾊,跟之前差不多,現在我們再看看之前出問題的那個例⼦(鏈接),權重和偏置都初始化為 2.0:
你將看到如下變化的曲線:
成功了!這次神經元的學習速度相當快,跟我們預期的那樣,如果你觀測的⾜夠仔細,你可以發現代價函數曲線要⽐二次代價函數訓練前⾯部分要陡很多,那個交叉熵導致的陡度讓我們⾼興,這正是我們期待的當神經元開始出現嚴重錯誤時能以最快速度學習。
4、過度擬合
這一節你將了解過度擬合的一般原因和解決策略。
諾貝爾獎獲得者,物理學家恩⾥科·費⽶有⼀次被問到他對⼀些同僚提出的⼀個數學模型的意⻅,這個數學模型嘗試解決⼀個重要的未解決的物理難題。模型和實驗⾮常匹配,但是費⽶卻對其產⽣了懷疑。他問模型中需要設置的⾃由參數有多少個。答案是“4”。費⽶回答道 6 :“我記得我的朋友約翰·馮·諾伊曼過去常說,有四個參數,我可以模擬⼀頭⼤象,⽽有五個參數,我還能讓他卷鼻⼦。”
這⾥,其實是說擁有大量的⾃由參數的模型能夠描述特別神奇的現象。即使這樣的模型能夠很好的擬合已有的數據,但并不表⽰是⼀個好模型。因為這可能只是因為模型中⾜夠的⾃由度使得它可以描述⼏乎所有給定⼤⼩的數據集,⽽不需要真正洞察現象的本質。所以發⽣這種情形時,模型對已有的數據會表現的很好,但是對新的數據很難泛化,對⼀個模型真正的測驗就是它對沒有⻅過的場景的預測能⼒。
費米和馮·諾伊曼對有四個參數的模型就開始懷疑了,我們⽤來對 MNIST 數字分類的 30 個隱藏神經元神經⽹絡擁有將近 24,000 個參數!當然很多,我們有 100 個隱藏元的⽹絡擁有將近80,000 個參數,⽽⽬前最先進的深度神經⽹絡包含百萬級或者⼗億級的參數。我們應當信賴這些結果么?
讓我們通過構造⼀個網絡泛華能⼒很差的例⼦使這個問題更清晰。我們的⽹絡有 30 個隱藏神經元,共 23,860 個參數,但是我們不會使⽤所有 50,000 幅 MNIST 訓練圖像,相反,我們只使⽤前 1,000 幅圖像。使⽤這個受限的集合,會讓泛化的問題突顯。我們按照之前同樣的⽅式,使⽤交叉熵代價函數,學習速率設置為 η = 0.5 ⽽⼩批量數據⼤⼩設置為 10,不過這⾥我們要訓練 400 個迭代期,⽐前⾯的要多⼀些,因為我們只⽤了少量的訓練樣本。
使⽤上面的結果,我們可以畫出當⽹絡學習時代價變化的情況:
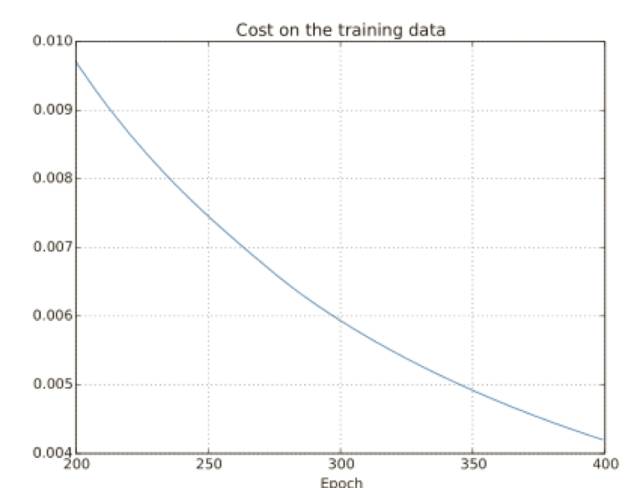
這看起來令人振奮,因為代價函數有⼀個光滑的下降,跟我們預期⼀致。注意,我只是展⽰了 200 到 399 迭代期的情況。
讓我們看看分類準確率在測試集上的表現:
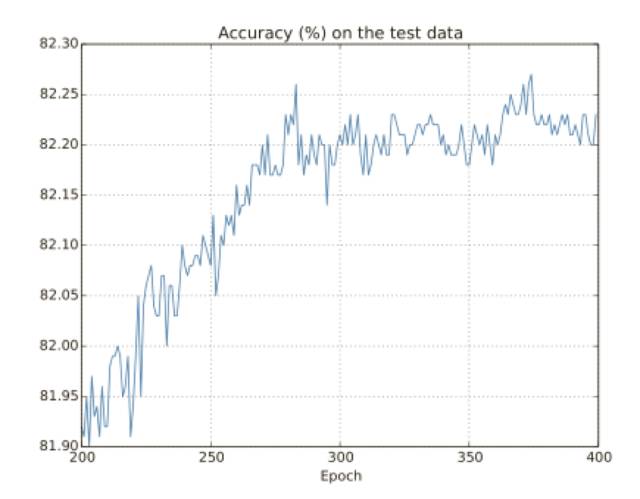
這里我還是聚焦到了后⾯的過程。在前 200 迭代期(圖中沒有顯⽰)中準確率提升到了 82%。然后學習逐漸變緩,最終,在 280 迭代期左右分類準確率就停⽌了增⻓,后⾯的迭代期,僅僅看到了在 280 迭代期準確率周圍隨機的⼩波動,將這幅圖和前⾯的圖進⾏對⽐,前⾯的圖中和訓練數據相關的代價持續平滑下降,如果我們只看那個代價,會發現我們模型的表現變得“更好”,但是測試準確率展⽰了提升只是⼀種假象,就像費⽶不⼤喜歡的那個模型⼀樣,我們的⽹絡在 280 迭代期后就不在能夠推⼴到測試數據上,所以這不是有⽤的學習,我們說⽹絡在 280迭代期后就過度擬合(overfitting)或者過度訓練(overtraining)了。
所以我們的網絡實際上在學習訓練數據集的特例,⽽不是能夠⼀般地進⾏識別,我們的⽹絡⼏乎是在單純記憶訓練集合,⽽沒有對數字本質進⾏理解能夠泛化到測試數據集上。
過度擬合是神經網絡的⼀個主要問題。這在現代⽹絡中特別正常,因為⽹絡權重和偏置數量巨⼤,為了⾼效地訓練,我們需要⼀種檢測過度擬合是不是發⽣的技術,這樣我們不會過度訓練,并且我們也想要找到⼀些技術來降低過度擬合的影響。
檢測過度擬合的明顯方法是使⽤上⾯的⽅法 —— 跟蹤測試數據集合上的準確率隨訓練變化情況,如果我們看到測試數據上的準確率不再提升,那么我們就停⽌訓練。當然,嚴格地說,這其實并⾮是過度擬合的⼀個必要現象,因為測試集和訓練集上的準確率可能會同時停⽌提升,當然,采⽤這樣的策略是可以阻⽌過度擬合的。
我們已經研究了只使⽤ 1,000 幅訓練圖像時的過度擬合問題。那么如果我們使⽤所有的50,000 幅圖像的訓練數據會發⽣什么?我們會保留所有其它的參數都⼀樣(30 個隱藏元,學習速率 0.5,小批量數據規模為 10),但是迭代期為 30 次,下圖展⽰了分類準確率在訓練和測試集上的變化情況。
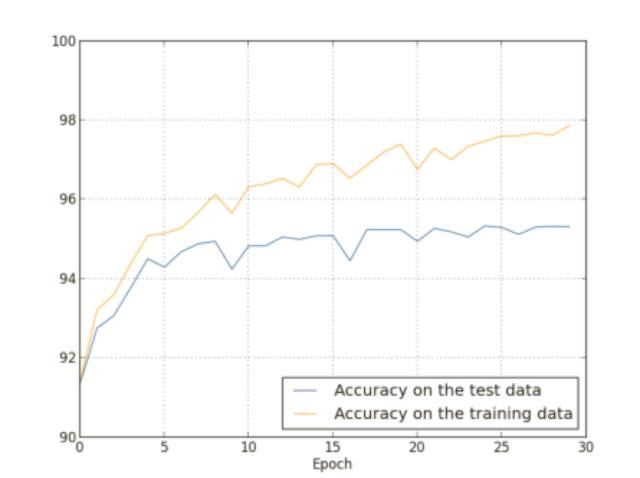
如你所⻅,測試集和訓練集上的準確率相⽐我們使⽤ 1,000 個訓練數據時相差更小。特別地,在訓練數據上的最佳的分類準確率 97.86% 只⽐測試集上的 95.33% 準確率⾼了 1.53%。⽽之前的例⼦中,這個差距是 17.73%!過度擬合仍然發⽣了,但是已經減輕了不少,我們的⽹絡從訓練數據上更好地泛化到了測試數據上,⼀般來說,最好的降低過度擬合的⽅式之⼀就是增加訓練樣本的量,有了⾜夠的訓練數據,就算是⼀個規模⾮常⼤的⽹絡也不⼤容易過度擬合,不幸的是,訓練數據其實是很難或者很昂貴的資源,所以這不是⼀種太切實際的選擇。
5、規范化
這一節你將了解用規范化方法來防止過度擬合的方法,但無法給出科學的解釋。
增加訓練樣本的數量是⼀種減輕過度擬合的方法,還有其他的⼀下⽅法能夠減輕過度擬合的程度嗎?⼀種可⾏的⽅式就是降低⽹絡的規模。然⽽,⼤的⽹絡擁有⼀種⽐⼩⽹絡更強的潛⼒,所以這⾥存在⼀種應⽤冗余性的選項,幸運的是,還有其他的技術能夠緩解過度擬合,即使我們只有⼀個固定的⽹絡和固定的訓練集合,這種技術就是規范化。
本節,我會給出⼀種最為常⽤的規范化手段 —— 有時候被稱為權重衰減(weight decay)或者 L2 規范化,L2 規范化的想法是增加⼀個額外的項到代價函數上,這個項叫做規范化項,下⾯是規范化的交叉熵:
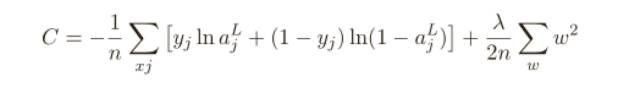
其中第⼀個項就是常規的交叉熵的表達式。第⼆個現在加⼊的就是所有權重的平⽅的和,然后使⽤⼀個因⼦ λ/2n 進⾏量化調整,其中 λ > 0 可以稱為規范化參數,⽽ n 就是訓練集合的⼤⼩,我們會在后⾯討論 λ 的選擇策略。
直覺地看,規范化的效果是讓網絡傾向于學習⼩⼀點的權重,其他的東西都⼀樣的。⼤的權重只有能夠給出代價函數第⼀項⾜夠的提升時才被允許,換⾔之,規范化可以當做⼀種尋找⼩的權重和最⼩化原始的代價函數之間的折中,這兩部分之前相對的重要性就由 λ 的值來控制了:λ 越⼩,就偏向于最⼩化原始代價函數,反之,傾向于⼩的權重。
現在,對于這樣的折中為何能夠減輕過度擬合還不是很清楚!但是,實際表現表明了這點。
為了構造這個例⼦,我們⾸先需要弄清楚如何將隨機梯度下降算法應⽤在⼀個規范化的神經網絡上。
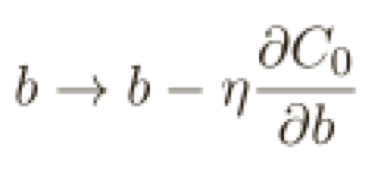
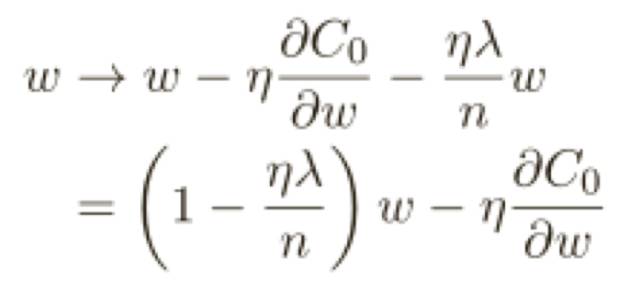
這正和通常的梯度下降學習規則相同,除了通過⼀個因⼦ 1−ηλ/n重新調整了權重 w,這種調整有時被稱為權重衰減,因為它使得權重變⼩,粗看,這樣會導致權重會不斷下降到 0,但是實際不是這樣的,因為如果在原始代價函數中造成下降的話其他的項可能會讓權重增加。
讓我們看看規范化給網絡帶來的性能提升吧。這⾥還會使⽤有 30 個隱藏神經元、⼩批量數據⼤⼩為 10,學習速率為 0.5,使⽤交叉熵的神經⽹絡,然⽽,這次我們會使⽤規范化參數為λ = 0.1,注意在代碼中,我們使⽤的變量名字為 lmbda。
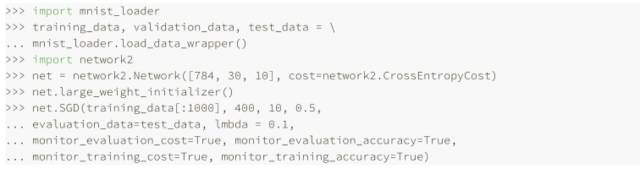
訓練集上的代價函數持續下降,和前⾯無規范化的情況⼀樣的規律:
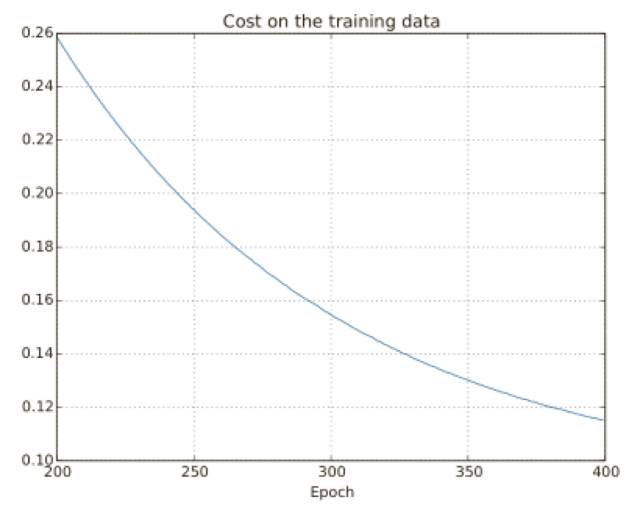
但是這次測試集上的準確率在整個 400 迭代期內持續增加:
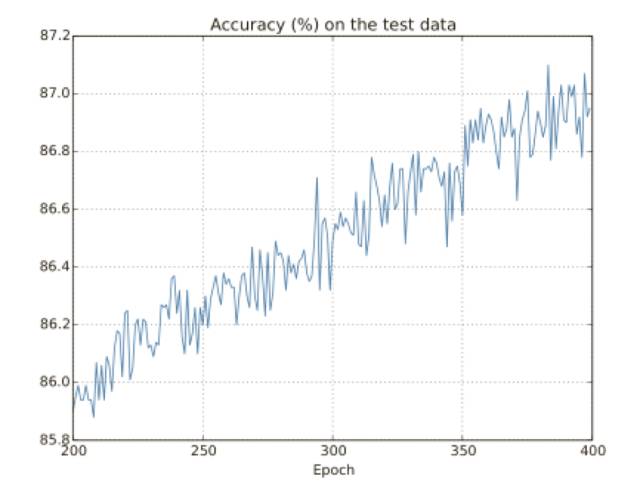
顯然,規范化的使用能夠解決過度擬合的問題,⽽且,準確率相當⾼了,最⾼處達到了 87.1%,相較于之前的 82.27%,因此,我們⼏乎可以確信在 400 迭代期之后持續訓練會有更加好的結果,看起來,經實踐檢驗,規范化讓⽹絡具有更好的泛化能⼒,顯著地減輕了過度擬合的影響。
我們已經看到了規范化在實踐中能夠減少過度擬合了,這是令⼈振奮的,不過,這背后的原因還不得而知!通常的說法是:⼩的權重在某種程度上,意味著更低的復雜性,也就對數據給出了⼀種更簡單卻更強⼤解釋,因此應該優先選擇,這雖然很簡短,不過暗藏了⼀些可能看起來會令⼈困惑的因素。
假設神經網絡⼤多數有很⼩的權重,這最可能出現在規范化的⽹絡中,更⼩的權重意味著⽹絡的⾏為不會因為我們隨便改變了⼀個輸⼊⽽改變太⼤,這會讓規范化⽹絡學習局部噪聲的影響更加困難,將它看做是⼀種讓單個的證據不會影響⽹絡輸出太多的⽅式。相對的,規范化⽹絡學習去對整個訓練集中經常出現的證據進⾏反應。對⽐看,⼤權重的⽹絡可能會因為輸⼊的微⼩改變⽽產⽣⽐較⼤的⾏為改變。所以⼀個⽆規范化的⽹絡可以使⽤⼤的權重來學習包含訓練數據中的噪聲的⼤量信息的復雜模型。簡⾔之,規范化⽹絡受限于根據訓練數據中常⻅的模式來構造相對簡單的模型,⽽能夠抵抗訓練數據中的噪聲的特性影響,我們的想法就是這可以讓我們的⽹絡對看到的現象進⾏真實的學習,并能夠根據已經學到的知識更好地進⾏泛化。
所以,傾向于更簡單的解釋的想法其實會讓我們覺得緊張。人們有時候將這個想法稱為“奧卡姆剃⼑原則”,然后就會熱情地將其當成某種科學原理來應⽤這個法則。但是,這就不是⼀個⼀般的科學原理,也沒有任何先驗的邏輯原因來說明簡單的解釋就⽐更為負責的解釋要好。
我們應當時時記住這⼀點,規范化的神經網絡常常能夠⽐⾮規范化的泛化能⼒更強,這只是⼀種實驗事實(empirical fact)。
6、棄權
這一節你將了解用相當激進的棄權(Dropout)防止過度擬合的技術。
棄權(Dropout)是⼀種相當激進的技術,和規范化不同,棄權技術并不依賴對代價函數的修改,⽽是,在棄權中,我們改變了⽹絡本⾝。
假設我們嘗試訓練⼀個網絡:
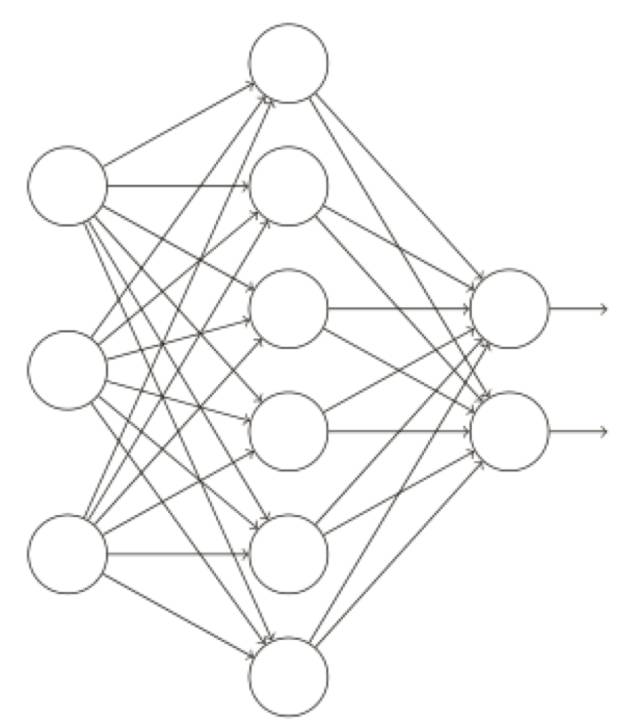
特別地,假設我們有⼀個訓練數據 x 和對應的目標輸出 y,通常我們會通過在⽹絡中前向傳播 x ,然后進⾏反向傳播來確定對梯度的貢獻,使⽤棄權技術,這個過程就改了。我們會從隨機(臨時)地刪除⽹絡中的⼀半的隱藏神經元開始,同時讓輸⼊層和輸出層的神經元保持不變。在此之后,我們會得到最終如下線條所⽰的⽹絡。注意那些被棄權的神經元,即那些臨時被刪除的神經元,⽤虛圈表⽰在圖中:
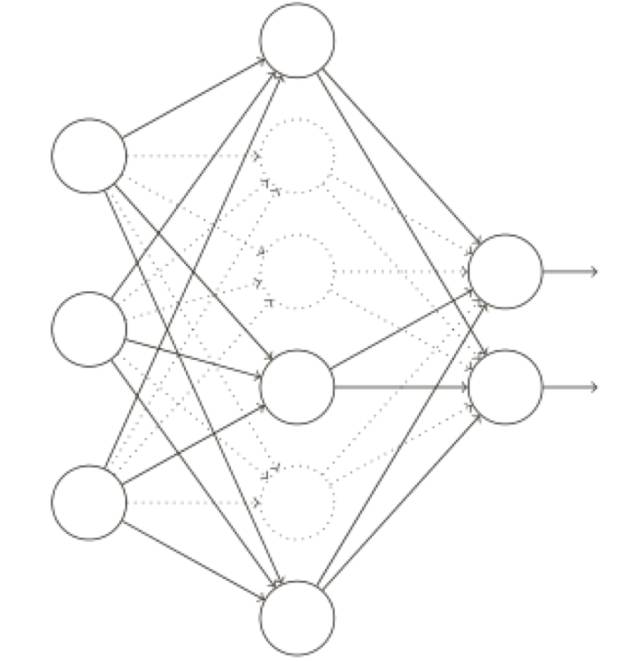
我們前向傳播輸⼊ x,通過修改后的⽹絡,然后反向傳播結果,同樣通過這個修改后的⽹絡,在⼀個小批量數據⼩批量的若⼲樣本上進⾏這些步驟后,我們對有關的權重和偏置進⾏更新。然后重復這個過程,⾸先重置棄權的神經元,然后選擇⼀個新的隨機的隱藏神經元的⼦集進⾏刪除,估計對⼀個不同的⼩批量數據的梯度,然后更新權重和偏置。
通過不斷地重復,我們的網絡會學到⼀個權重和偏置的集合。當然,這些權重和偏置也是在⼀半的隱藏神經元被棄權的情形下學到的,當我們實際運⾏整個⽹絡時,是指兩倍的隱藏神經元將會被激活,為了補償這個,我們將從隱藏神經元元出去的權重減半。
為什么我們會指望這樣的⽅法能夠進⾏規范化呢?為了解釋所發⽣的事,我希望你停下來想⼀下沒有標準(沒有棄權)的訓練⽅式。特別地,想象⼀下我們訓練⼏個不同的神經⽹絡,都使⽤同⼀個訓練數據,當然,⽹絡可能不是從同⼀初始狀態開始的,最終的結果也會有⼀些差異。出現這種情況時,我們可以使⽤⼀些平均或者投票的⽅式來確定接受哪個輸出。例如,如果我們訓練了五個⽹絡,其中三個把⼀個數字分類成“3”,那很可能它是“3”,另外兩個可能就犯了錯誤。這種平均的方式通常是⼀種強⼤(盡管代價昂貴)的⽅式來減輕過度擬合,原因在于不同的⽹絡可能會以不同的⽅式過度擬合,平均法可能會幫助我們消除那樣的過度擬合。
那么這和棄權有什么關系呢?啟發式地看,當我們棄權掉不同的神經元集合時,有點像我們在訓練不同的神經網絡。所以,棄權過程就如同⼤量不同⽹絡的效果的平均那樣,不同的⽹絡會以不同的⽅式過度擬合了,所以,棄權過的⽹絡的效果會減輕過度擬合。
棄權技術的真正衡量是它已經在提升神經⽹絡性能上應用得相當成功,在訓練⼤規模深度⽹絡時尤其有⽤,這樣的⽹絡中過度擬合問題經常特別突出。
7、人為擴展訓練數據
我們前面看到了 MNIST 分類準確率在我們使⽤ 1,000 幅訓練圖像時候下降到了 80% 中間的準確率。這種情況并不奇怪,因為更少的訓練數據意味著我們的⽹絡接觸更少的⼈類⼿寫的數字中的變化。讓我們訓練 30 個隱藏神經元的⽹絡,使⽤不同的訓練數據集,來看看性能的變化情況。我們使⽤⼩批量數據⼤⼩為 10,學習速率為 η = 0.5,規范化參數是λ = 5.0,交叉熵代價函數,我們在全部訓練數據集合上訓練 30 個迭代期,然后會隨著訓練數據量的下降⽽成⽐例增加迭代期的數量。
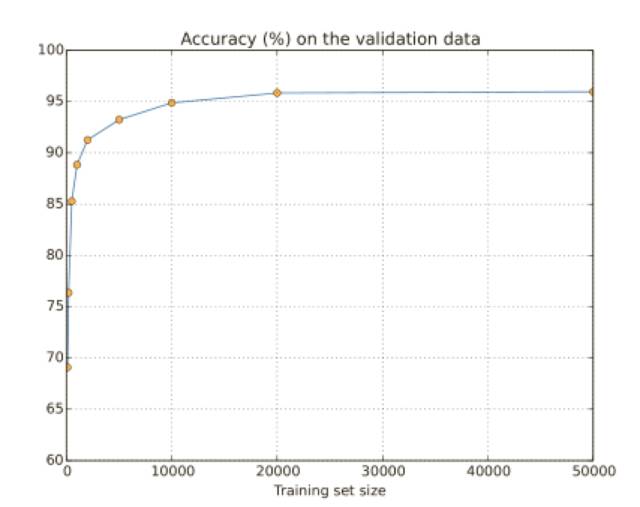
分類準確率在使⽤更多的訓練數據時提升了很⼤。根據這個趨勢的話,提升會隨著更多的數據⽽不斷增加。
獲取更多的訓練樣本其實是很好的想法。不幸的是,這個⽅法代價很⼤,在實踐中常常是很難達到的,不過,還有⼀種⽅法能夠獲得類似的效果,那就是⼈為擴展訓練數據,假設我們使⽤⼀個 5 的 MNIST 訓練圖像:

將其進⾏旋轉,比如說 15 度:

這還是會被設別為同樣的數字的,但是在像素層級這和任何⼀幅在 MNIST 訓練數據中的圖像都不相同,所以將這樣的樣本加⼊到訓練數據中是很可能幫助我們的⽹絡學會更多如何分類數字,⽽且,顯然我們不限于只增加這幅圖像,我們可以在所有的 MNIST 訓練樣本上通過很多小的旋轉擴展訓練數據,然后使⽤擴展后的訓練數據來提升我們⽹絡的性能。
這個想法非常強⼤并且已經被⼴發應⽤了。讓我們從⼀篇論⽂看看⼀些結果,這⽚論⽂中,作者在 MNIST 上使⽤了⼏個的這種想法的變化⽅式。其中⼀種他們考慮的⽹絡結構其實和我們已經使⽤過的類似 —— ⼀個擁有 800 個隱藏元的前饋神經⽹絡,使⽤了交叉熵代價函數。在標準的 MNIST 訓練數據上運⾏這個⽹絡,得到了 98.4% 的分類準確率,他們不只旋轉,還轉換和扭曲圖像來擴展訓練數據,通過在這個擴展后的數據集上的訓練,他們提升到了 98.9% 的準確率,然后還在“彈性扭曲”的數據上進⾏了實驗,這是⼀種特殊的為了模仿⼿部肌⾁的隨機抖動的圖像扭曲⽅法,通過使⽤彈性扭曲擴展的數據,他們最終達到了 99.3% 的分類準確率,他們通過展⽰訓練數據的所有類型的變化形式來擴展⽹絡的經驗。
8、權重初始化
創建了神經網絡后,我們需要進⾏權重和偏置的初始化,之前的⽅式就是根據獨⽴⾼斯隨機變量來選擇權重和偏置,其被歸⼀化為均值為 0,標準差 1。這個⽅法⼯作的還不錯,但是⾮常特別,所以值得去重新探討它,看看是否能尋找⼀些更好的⽅式來設置初始的權重和偏置,這也許能幫助我們的⽹絡學習得更快。
結果表明,我們可以比使⽤歸⼀化的⾼斯分布做得更好,為什么?假設我們使⽤⼀個有⼤量輸⼊神經元的⽹絡,⽐如說 1,000 個,假設,我們已經使⽤歸⼀化的⾼斯分布初始化了連接第⼀個隱藏層的權重,現在我將注意⼒集中在這⼀層的連接權重上,忽略⽹絡其他部分:
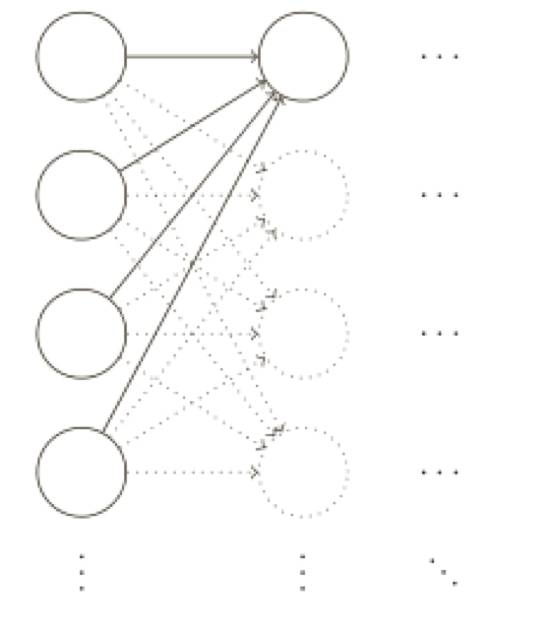
為了簡化,假設我們使用訓練輸⼊ x,其中⼀半的輸⼊神經元值為 1,另⼀半為 0,以下的論點更普遍適⽤,但你可以從這種特殊情況得到要點。讓我們考慮隱藏神經元輸⼊的帶權和z =∑j W j X j+ b。其中 500 個項消去了,因為對應的輸⼊ X j 為 0。所以 z 是遍歷總共 501 個歸⼀化的⾼斯隨機變量的和,包含 500 個權重項和額外的 1 個偏置項,因此 z 本⾝是⼀個均值為 0標準差為√ 501 ≈ 22.4 的⾼斯分布。z 其實有⼀個⾮常寬的⾼斯分布,完全不是⾮常尖的形狀:
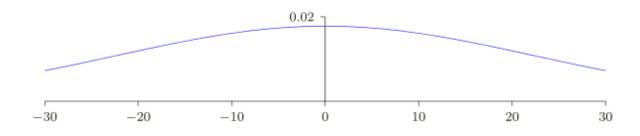
尤其是,我們可以從這幅圖中看出 |z| 會變得非常的⼤,即 z ≫ 1 或者 z ≪−1。如果是這樣,隱藏神經元的輸出 σ(z) 就會接近 1 或者 0。也就表⽰我們的隱藏神經元會飽和。所以當出現這樣的情況時,在權重中進⾏微⼩的調整僅僅會給隱藏神經元的激活值帶來極其微弱的改變。⽽這種微弱的改變也會影響⽹絡中剩下的神經元,然后會帶來相應的代價函數的改變。結果就是,這些權重在我們進⾏梯度下降算法時會學習得⾮常緩慢。
假設我們有⼀個有 n 個輸入權重的神經元。我們會使⽤均值為 0 標準差為 1/ √ n 的⾼斯隨機分布初始化這些權重。也就是說,我們會向下擠壓⾼斯分布,讓我們的神經元更不可能飽和,我們會繼續使⽤均值為 0 標準差為 1 的⾼斯分布來對偏置進⾏初始化,后⾯會告訴你原因。有了這些設定,帶權和 z =∑jW jX j+ b 仍然是⼀個均值為 0,不過有尖銳峰值的⾼斯分布。假設,我們有 500 個值為 0 的輸⼊和 500 個值為 1 的輸⼊。那么很容易證明 z 是服從均值為 0 標準差為√ 3/2 = 1.22... 的⾼斯分布。
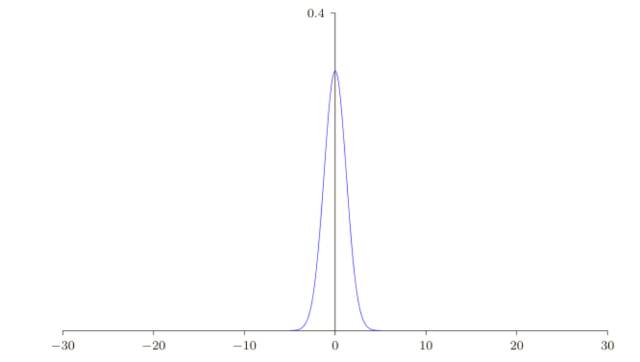
這樣的⼀個神經元更不可能飽和,因此也不大可能遇到學習速度下降的問題,讓我們在 MNIST 數字分類任務上⽐較⼀下新舊兩種權重初始化⽅式,同樣,還是使⽤ 30 個隱藏元,⼩批量數據的⼤⼩為 10,規范化參數 λ = 5.0,然后是交叉熵代價函數。我們將學習速率從 η = 0.5 降到 0.1,因為這樣會讓結果在圖像中表現得更加明顯。
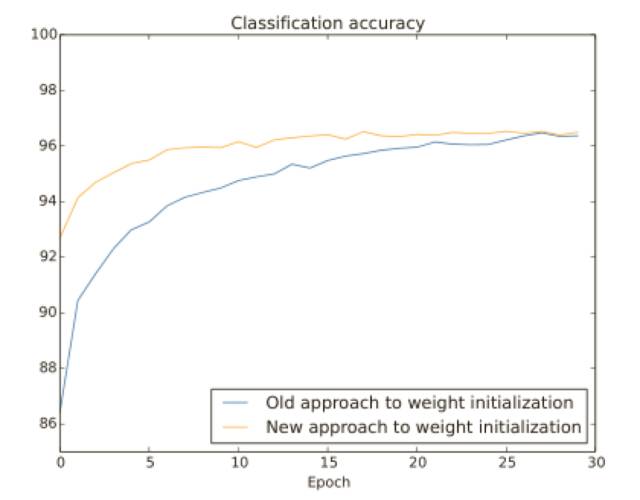
兩種情形下,我們在 96% 的準確率上重合了。最終的分類準確率⼏乎完全⼀樣。但是新的初始化技術帶來了速度的提升,在第⼀種初始化⽅式的分類準確率在 87% 以下,⽽新的⽅法已經⼏乎達到了 93%。看起來的情況就是我們新的關于權重初始化的⽅式將訓練帶到了⼀個新的境界,讓我們能夠更加快速地得到好的結果。
9、寬泛策略
直到現在,我們還沒有解釋對諸如學習速率 η,規范化參數 λ 等等超參數選擇的⽅法,我只是給出那些效果很好的值⽽已,實踐中,當你使⽤神經網絡解決問題時,尋找好的超參數其實是很困難的⼀件事。例如,我們要解決 MNIST 問題,開始時對于選擇什么樣的超參數⼀⽆所知。假設,剛開始的實驗中選擇前⾯章節的參數都是運⽓較好,但在使⽤學習速率 η=10.0 ⽽規范化參數 λ = 1000.0,下⾯是我們的⼀個嘗試:
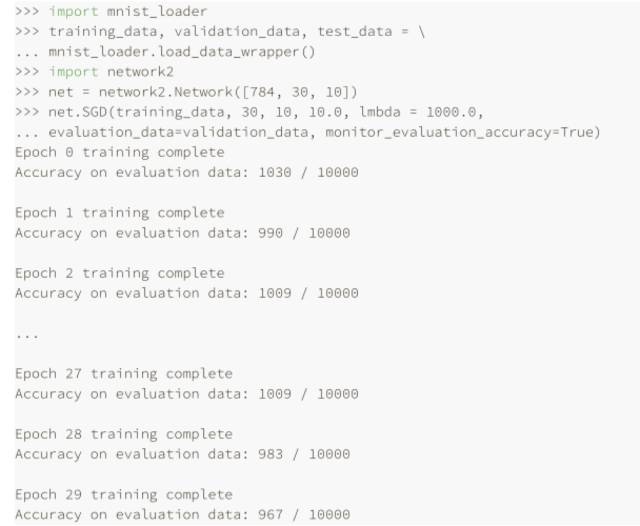
我們分類準確率并不比隨機選擇更好,⽹絡就像隨機噪聲產⽣器⼀樣,你可能會說,“這好辦,降低學習速率和規范化參數就好了。”不幸的是,你并不先驗地知道這些就是需要調整的超參數。可能真正的問題出在 30 個隱藏元中,本身就不能很有效,不管我們如何調整其他的超參數都沒有作⽤的?可能我們真的需要⾄少 100 個隱藏神經元?或者是 300個隱藏神經元?或者更多層的⽹絡?或者不同輸出編碼⽅式?可能我們的⽹絡⼀直在學習,只是學習的回合還不夠?可能 minibatch 的太⼩了?可能我們需要切換成⼆次代價函數?可能我們需要嘗試不同的權重初始化⽅法?等等。很容易就在超參數的選擇中迷失了⽅向。如果你的⽹絡規模很⼤,或者使⽤了很多的訓練數據,這種情況就很令⼈失望了,因為⼀次訓練可能就要⼏個⼩時甚⾄⼏天乃⾄⼏周,最終什么都沒有獲得。如果這種情況⼀直發⽣,就會打擊你的⾃信⼼。可能你會懷疑神經⽹絡是不是適合你所遇到的問題?可能就應該放棄這種嘗試了?
假設,我們第⼀次遇到 MNIST 分類問題。剛開始,你很有激情,但是當第⼀個神經⽹絡完全失效時,你會就得有些沮喪,此時就可以將問題簡化,丟開訓練和驗證集合中的那些除了 0 和 1的那些圖像,然后試著訓練⼀個⽹絡來區分 0 和 1,不僅僅問題⽐ 10 個分類的情況簡化了,同樣也會減少 80% 的訓練數據,這樣就給出了 5 倍的加速。這樣可以保證更快的實驗,也能給予你關于如何構建好的網絡更快的洞察。
你通過簡化網絡來加速實驗進⾏更有意義的學習,如果你相信 [784,10] 的⽹絡更可能⽐隨機更加好的分類效果,那么就從這個⽹絡開始實驗,這會⽐訓練⼀個 [784,30,10] 的⽹絡更快,你可以進⼀步嘗試后⼀個。
你可以通過提⾼監控的頻率來在試驗中獲得另⼀個加速了,比如我們將訓練數據減少到前 1,000 幅 MNIST 訓練圖像。讓我們嘗試⼀下,看看結果:
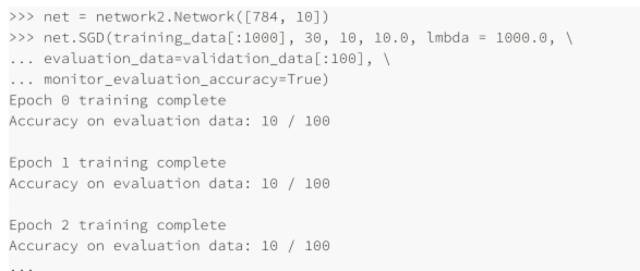
在上⾯的例⼦中,我設置 λ=1000.0,跟我們之前⼀樣。但是因為這⾥改變了訓練樣本的個數,我們必須對 λ 進⾏調整以保證權重下降的同步性,這意味著改變 λ =20.0,如果我們這樣設置,則有:
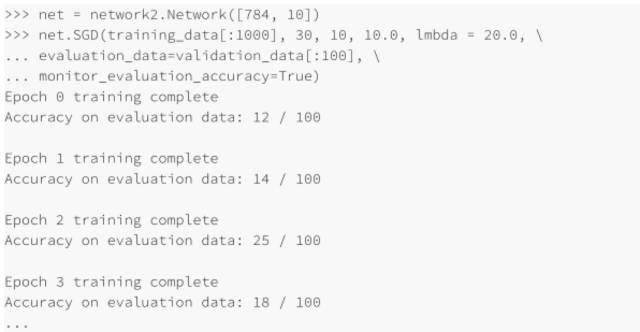
哦也!現在有了信號了,不是非常糟糕的信號,卻真是⼀個信號。我們可以基于這點,來改變超參數從⽽獲得更多的提升,可能我們猜測學習速率需要增加(你可以能會發現,這只是⼀個不⼤好的猜測,原因后⾯會講,但是相信我)所以為了測試我們的猜測就將 η 調整⾄ 100.0:
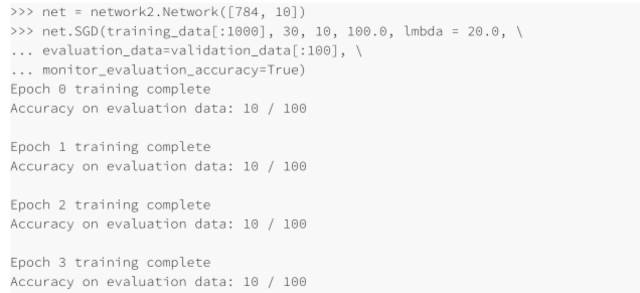
這并不好!告訴我們之前的猜測是錯誤的,問題并不是學習速率太低了,所以,我們試著將η 將⾄ η = 1.0:
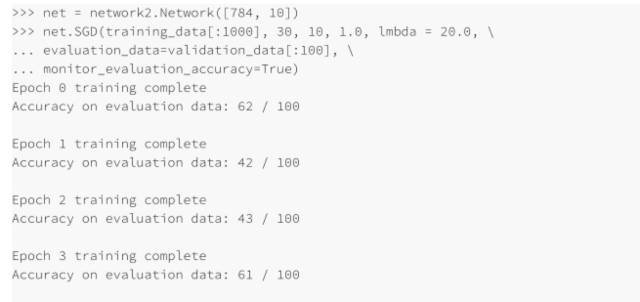
這樣好點了!所以我們可以繼續,逐個調整每個超參數,慢慢提升性能。⼀旦我們找到⼀種提升性能的 η 值,我們就可以嘗試尋找好的值。然后按照⼀個更加復雜的⽹絡架構進⾏實驗,假設是⼀個有 10 個隱藏元的⽹絡。然后繼續調整 η 和 λ。接著調整成 20 個隱藏元。然后將其他的超參數調整再調整。如此進⾏,在每⼀步使用我們 hold out 驗證數據集來評價性能,使⽤這些度量來找到越來越好的超參數,當我們這么做的時候,⼀般都需要花費更多時間來發現由于超參數改變帶來的影響,這樣就可以⼀步步減少監控的頻率。
所有這些作為⼀種寬泛的策略看起來很有前途。
10、學習速率
假設我們運⾏了三個不同學習速率(η = 0.025、η = 0.25、η = 2.5)的 MNIST 網絡,我們會像前⾯介紹的實驗那樣設置其他的超參數,進⾏30 回合,minibatch ⼤⼩為 10,然后λ = 5.0,我們同樣會使⽤整個 50,000 幅訓練圖像,下⾯是⼀副展⽰了訓練代價的變化情況的圖:
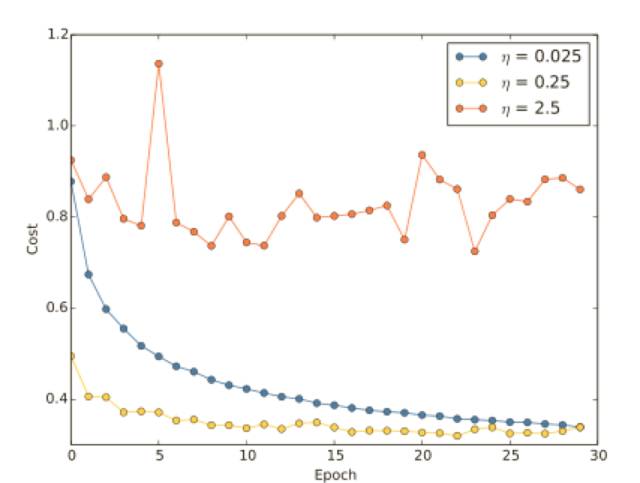
使⽤ η = 0.025,代價函數平滑下降到最后的回合,使⽤ η = 0.25,代價剛開始下降,在⼤約20 回合后接近飽和狀態,后⾯就是微小的震蕩和隨機抖動,最終使⽤ η = 2.5 代價從始⾄終都震蕩得⾮常明顯,為了理解震蕩的原因,回想⼀下隨機梯度下降其實是期望我們能夠逐漸地抵達代價函數的⾕底的:
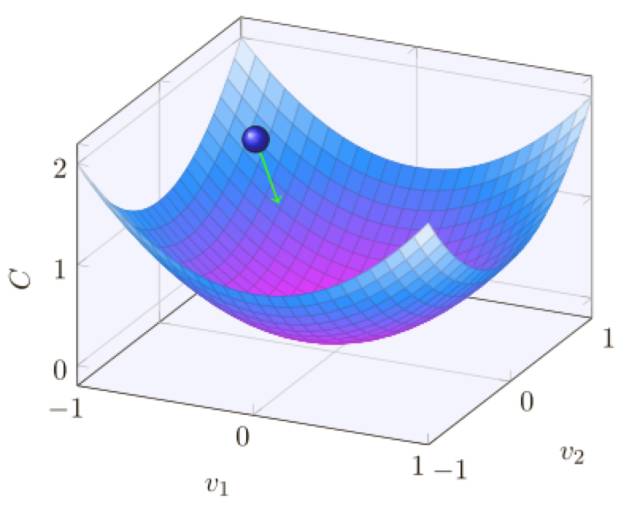
然⽽,如果 η 太大的話,步⻓也會變⼤可能會使得算法在接近最⼩值時候⼜越過了⾕底,這在η = 2.5 時⾮常可能發⽣。當我們選擇 η = 0.25 時,初始⼏步將我們帶到了⾕底附近,但⼀旦到達了⾕底,⼜很容易跨越過去,⽽在我們選擇 η = 0.025 時,在前 30 回合的訓練中不再受到這個情況的影響。當然,選擇太⼩的學習速率,也會帶來另⼀個問題 —— 隨機梯度下降算法變慢了,⼀種更加好的策略其實是,在開始時使⽤ η = 0.25,隨著越來越接近⾕底,就換成 η = 0.025,現在,我們就聚焦在找出⼀個單獨的好的學習速率的選擇η。
所以,有了這樣的想法,我們可以如下設置 η。⾸先,我們選擇在訓練數據上的代價⽴即開始下降⽽非震蕩或者增加時作為 η 的閾值的估計,這個估計并不需要太過精確,你可以估計這個值的量級,⽐如說從 η = 0.01 開始,如果代價在訓練的前⾯若⼲回合開始下降,你就可以逐步地嘗試 η = 0.1,1.0,...,直到你找到⼀個 η 的值使得在開始若⼲回合代價就開始震蕩或者增加,相反,如果代價在 η = 0.01 時就開始震蕩或者增加,那就嘗試 η = 0.001,0.0001,... 直到你找到代價在開始回合就下降的設定,按照這樣的⽅法,我們可以掌握學習速率的閾值的量級的估計,你可以選擇性地優化估計,選擇那些最⼤的 η,⽐⽅說 η = 0.5 或者 η = 0.2。
11、小批量數據大小
我們應該如何設置小批量數據的⼤⼩?為了回答這個問題,讓我們先假設正在進⾏在線學習,也就是說使⽤⼤⼩為 1 的⼩批量數據。
我們使用100 的小批量數據的學習規則如下:
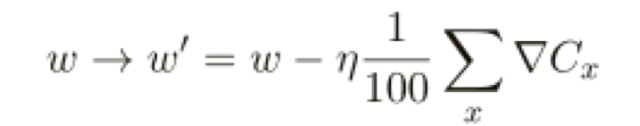
這⾥是對小批量數據中所有訓練樣本求和,而在線學習是:
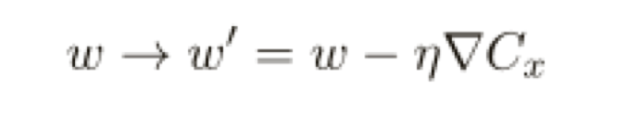
即使它僅僅是 50 倍的時間,結果仍然⽐直接在線學習更好,因為我們在線學習更新得太過頻繁了。
所以,選擇最好的小批量數據⼤⼩也是⼀種折衷,太⼩了,你不會⽤上很好的矩陣庫的快速計算,太⼤,你是不能夠⾜夠頻繁地更新權重的,你所需要的是選擇⼀個折衷的值,可以最⼤化學習的速度,幸運的是,⼩批量數據⼤⼩的選擇其實是相對獨⽴的⼀個超參數(⽹絡整體架構外的參數),所以你不需要優化那些參數來尋找好的⼩批量數據⼤⼩,因此,可以選擇的⽅式就是使⽤某些可以接受的值(不需要是最優的)作為其他參數的選擇,然后進⾏不同⼩批量數據⼤⼩的嘗試,像上⾯那樣調整 η。畫出驗證準確率的值隨時間(⾮回合)變化的圖,選擇哪個得到最快性能的提升的⼩批量數據⼤⼩。得到了 ⼩批量數據⼤⼩,也就可以對其他的超參數進⾏優化了。
跟隨上面看的經驗并不能幫助你的⽹絡給出絕對最優的結果,但是很可能給你⼀個好的開始和⼀個改進的基礎,特別地,我已經非常獨⽴地討論了超參數的選擇。實踐中,超參數之間存在著很多關系,你可能使⽤ η 進⾏試驗,發現效果不錯,然后去優化 λ,發現這⾥⼜對 η 混在⼀起了,在實踐中,⼀般是來回往復進⾏的,最終逐步地選擇到好的值。總之,啟發式規則其實都是經驗,不是⾦規⽟律。你應該注意那些沒有效果的嘗試的信號,然后樂于嘗試更多試驗,特別地,這意味著需要更加細致地監控神經⽹絡⾏為,特別是驗證集上的準確率。
設定超參數的挑戰讓⼀些人抱怨神經⽹絡相⽐較其他的機器學習算法需要⼤量的⼯作進⾏參數選擇。我也聽到很多不同的版本:“的確,參數完美的神經⽹絡可能會在這問題上獲得最優的性能。但是,我可以嘗試⼀下隨機森林(或者 SVM 或者……這⾥腦補⾃⼰偏愛的技術)也能夠⼯作的。我沒有時間搞清楚那個最好的神經⽹絡。”當然,從⼀個實踐者角度,肯定是應⽤更加容易的技術,這在你剛開始處理某個問題時尤其如此,因為那時候,你都不確定⼀個機器學習算法能夠解決那個問題。但是,如果獲得最優的性能是最重要的⽬標的話,你就可能需要嘗試更加復雜精妙的知識的⽅法了,如果機器學習總是簡單的話那是太好不過了,但也沒有⼀個應當的理由說機器學習⾮得這么簡單。
洋洋灑灑這么多,其實也只是接觸了些皮毛,但相對于很多書本關于公式和代碼的堆砌,這寫內容的確給人以不少啟迪,讓你知道為什么這么做,而讓筆者吃驚的是,神經網絡的參數調整很多竟然是沒有明確科學依據的,更多的還要依賴經驗。