華為全閃存的核“芯”
對于華為存儲自研存儲領域的相關芯片,外界一直充滿好奇。縱觀業界,Avago并購LSI,Cavium并購QLogic,博通并購博科,皆因芯片的技術能力,在芯片并購的大浪潮之下,為什么華為存儲反其道而行之,自研芯片?特別是在火熱的閃存存儲領域,華為自研了哪些芯片?其芯片未來又是如何演進的呢?本文將為您一一解惑。
自研芯片驅動力
全球范圍內的企業都面臨數字洪流的影響,快速增長的數據規模、越來越高要求的業務處理性能和存儲效率成為企業面臨的重大挑戰。作為企業數字化轉型的利器,全閃存天生高性能的優勢,為加速關鍵業務帶來新的動力。
全閃存的高速發展,促使介質快速演進,介質性能由量變達到質變(3D XPoint介質比NAND介質快1000倍);介質和應用(AR/VR等)的發展,對網絡也提出更低時延的要求;摩爾周期延長,導致CPU性能提升放緩,計算能力需求缺口增大;介質與網絡接口、CPU技術發展不均衡,推動存儲技術又一輪變革。
面對存儲技術變革的挑戰,為滿足客戶業務日益增長的訴求,華為存儲提出以All IP為基礎,以All Cloud和All Flash為牽引,芯片、網絡設備、應用垂直整合的策略。通過垂直整合,實現資源***化利用,向客戶提供具有更強性能的產品。
自研芯片技術創新
2016年華為發布新一代全閃存陣列OceanStor Dorado V3,具備高達400萬IOPS時,仍保持0.5ms穩定時延的卓越性能,能充分發揮閃存效率,滿足關鍵重載業務處理能力。華為存儲構建了從前端協議處理芯片、IO處理加速芯片、SSD控制芯片端到端的硬件芯片平臺,為全閃存存儲帶來創新的加速方案,端到端傳輸性能提升200%。
一.協議處理芯片
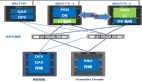
1.SmartIO融合多協議,減少連接線纜,簡化組網,降低TCO
SmartIO卡使用華為存儲協議處理芯片,同時支持8G/16G FC、10G FCoE、10GE、iWARP協議,客戶可將IP 和FC數據流量整合到同一個接口芯片中。
通過支持融合組網,10GE支持FCoE/iSCSI/iWARP/CIFS/NFS多協議時,無需更換任何物理部件,支持與任何10GE存儲主機端口進行連接。在10GE或8/16Gb FC組網下只需要更換光模塊部件,無需更換卡件,支持任意協議轉換。使布線減少1/3,接口卡物理部件減少75%,降低客戶初始投資成本。
2.RDMA技術,降低60%鏈路時延
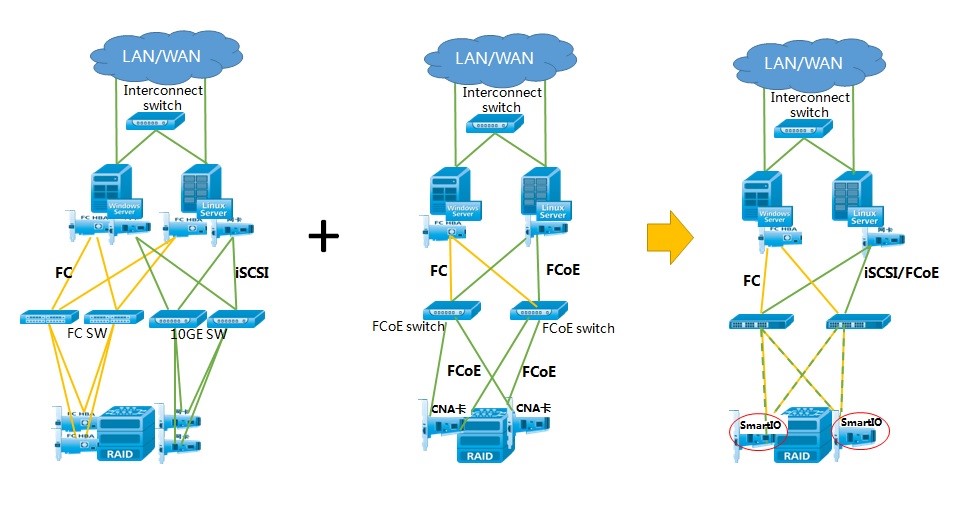
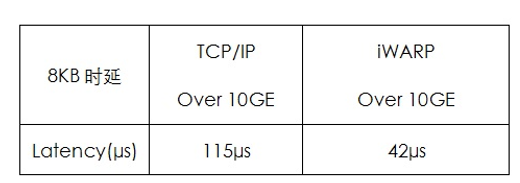
RDMA(Remote Direct Memory Access)是“遠程直接數據存取”,通過網絡把數據直接傳入計算機的存儲區,將數據從一個系統快速移動到遠程系統存儲器中,而不對操作系統造成任何影響,這樣就不需要用到多少計算機的處理能力。因而能騰出總線空間和CPU周期,用于改進應用系統性能。華為存儲協議處理芯片支持硬件級RDMA,在多個存儲控制器之間通過RDMA進行數據傳輸和交換,從而降低鏈路上時延超過60%,極大地提升客戶在多并發和高負載業務下的處理效率。基于10GE,在8并發、8KB IO大小,時延測試結果如下:
3.針對WAN優化,減少廣域網擁塞,提升復雜組網場景下遠程復制帶寬
WAN優化即廣域網優化,通過各種技術手段削減廣域網數據傳輸量、優化廣域網上的數據通信,提升廣域網帶寬利用率。WAN優化從部署方式上分為單邊優化和雙邊優化:單邊優化主要采用流控和TCP優化技術;雙邊優化主要采用緩存和壓縮技術。
華為存儲協議處理芯片內嵌QoS流控和TCP擁塞算法技術,在客戶復雜組網場景,比如連接不同地區的局域網或城域網的計算機通信的遠程網,甚至跨接很大的物理范圍,所覆蓋的范圍從幾十公里到幾百公里連接多個城市情況下,通過實時偵測網絡數據包RTT時延、丟包率、ECN等,配合多種TCP擁塞算法,調整發送和接收策略,包括重試策略、收/發Buffer窗口、智能流控等手段,動態的針對某些鏈路傳輸擁塞進行規避和緩解,達到比普通網卡跑得更快的目的。WAN加速在復雜組網下可提升65%~400%的廣域網性能。
二.IO處理加速芯片
云服務時代帶來數據超預期增長的同時,也帶來了大量的重復數據,這些重復數據給企業帶來的價值十分有限,卻大量占用存儲空間、增加能耗和散熱成本,而且會降低系統的數據訪問性能、消耗企業有限的IT預算。企業迫切希望有一種方法能夠保證原有數據的訪問性能,并在此基礎上減少重復數據。
業內普遍采用重刪和壓縮技術來解決這個問題,但是重刪壓縮涉及到大量的指紋和壓縮、解壓縮算法,對CPU占用率較高,一旦開啟會顯著影響業務性能,因此傳統存儲都采用后重刪壓縮技術。對用戶來說,后重刪壓縮技術無法減少客戶預留存儲空間,不能減少***購置成本,同時更多的數據寫入,也影響SSD壽命。
華為IO處理加速芯片集成壓縮、解壓算法引擎,將壓縮和解壓縮等比較消耗計算資源的工作卸載到算法引擎,有效降低CPU負載。根據實際測試,在順序大IO場景下,CPU占用率減少24.6%,IOPS提升342.4%,時延縮短77.4%。
三.SSD控制芯片
華為自研SSD使用新一代自研的SSD控制芯片,采用了計算能力更強的Cortex-A9芯片,支持DDR4,多達18個NAND Flash通道,采用了硬件FTL(Flash Translation Layer)技術加速IO處理,實現200K IOPS能力,達到業界領先水平。
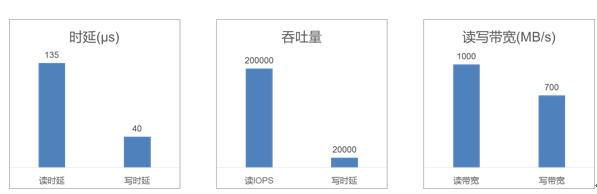
華為自研SSD性能數據
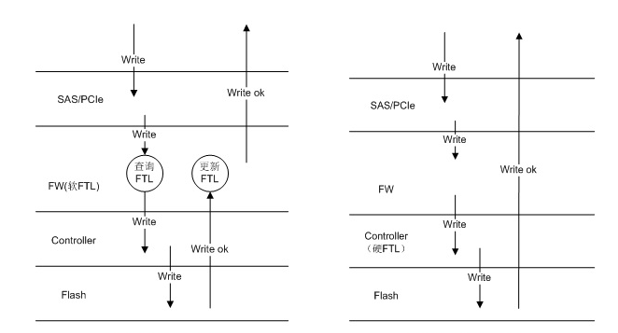
1. 硬件FTL,低負載時延比業界低20%
FTL(Flash Translation Layer)是SSD盤片內部的一個核心數據結構,用來保存用戶LBA到SSD盤內物理頁面的映射關系,用戶讀寫數據時帶下來一個LBA地址,SSD盤接收到以后,從FTL表中查詢到該LBA地址所對應的物理頁面,即可實現數據的讀取。傳統的SSD讀取數據的時候,SSD內部控制軟件查找到LBA地址對應的物理地址,然后再從Flash中讀取對應的數據返回給主機;寫入數據的時候,軟件寫入完畢后,再去更新FTL映射表。華為自研SSD使用硬件加速FTL表管理,所有讀取和寫入FTL的操作全部由硬件完成,減少軟件交互次數,減小IO的延時,在低負載場景下時延低至40μs,比業界低20%。
2. FlashLink技術保障全閃存陣列,實現平均穩定時延0.5ms
FlashLink技術是基于華為自研SSD盤和自研存儲操作系統,實現盤控聯動配合的軟硬件垂直優化技術,保障華為OceanStor Dorado V3全閃存存儲系統實現平均穩定時延0.5ms。

FlashLink技術示意圖
冷熱數據分區提供多個數據分區,自研存儲操作系統在訪問SSD盤片時,將數據的冷熱標示發給SSD,SSD控制芯片根據數據冷熱標識將冷熱數據分開存放,從而降低SSD垃圾回收的搬移數據量,寫放大降低約40%,時延降低20%。
IO優先級調度提供多個IO優先級調度能力,為保證穩定時延,自研存儲操作系統對IO優先級別進行了標識。比如,主機讀請求的優先級高于Flash Cache刷盤請求,Flash Cache刷盤寫請求優先級高于異步復制的后臺拷貝IO。IO優先級隨著讀寫請求一起發給SSD,SSD控制芯片接收到IO時,根據IO的優先級標識優先處理高優先級IO,從而實現端到端的IO優先級控制,保障優先的業務數據讀寫在***順序響應。
總結
華為存儲在自研芯片研發上持續投入和技術創新,幫助企業應對數字洪流挑戰,進行數字化轉型。
協議處理芯片以All IP為戰略,覆蓋前端網絡、交換網絡、后端網絡、復制/雙活網絡,構建大規模、低時延網絡能力;IO處理加速芯片以SOC為方向,集成存儲和網絡加速功能,持續優化計算、存儲、網絡能力;SSD控制芯片以介質為核心,匹配介質演進節奏,針對介質特性進行優化,充分發揮新介質優勢。
通過技術創新和軟硬件芯片垂直優化,華為存儲致力于消除CPU、介質、網絡發展不均衡導致的鴻溝,為客戶提供更快、更好、更省的產品和解決方案,與客戶一起實現商業成功。