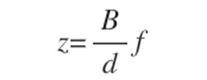遞歸卷積神經網絡在解析和實體識別中的應用
解析用戶的真實意圖
人類語言與計算機語言不同,人類的語言是沒有結構的,即使存在一些語法規則,這些規則往往也充滿著歧義。在有大量用戶輸入語料的情況下,我們需要根據用戶的輸入,分析用戶的意圖。比如我們想看看一個用戶有沒有購買某商品的想法,此時就必須使用解析算法,將用戶的輸入轉換成結構化的數據,并且在此結構上提取出有用的信息。
NLP 解析算法的一般步驟是分詞、標記詞性、句法分析。分詞和標記詞性等,可以用條件隨機場 (Conditional Random Field),隱馬爾可夫模型 (Hidden Markov Model) 等模型解決,近年來也有用神經網絡來做的,相對比較成熟,所以暫時不討論。本文主要討論一下最主要的一步,句法分析。
兩種句法分析工具
目前的句法分析工具,主要分為依存文法 (Dependency Grammar) 與成分分析 (Constituency Relation) 兩大類。
成分分析將文本劃分為子短語。
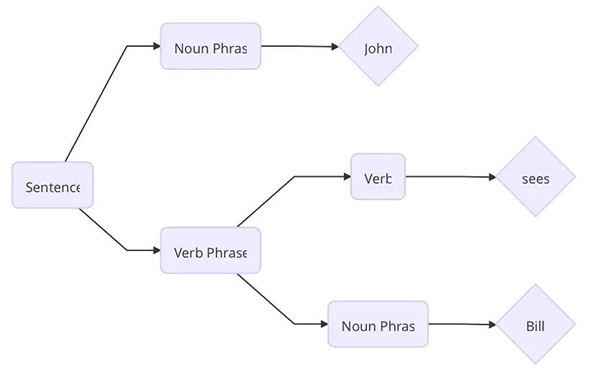
句子 John sees Bill 被劃分成了如上圖的結構。首先單詞 Bill 是一個名詞短語,sees 是一個動詞,根據預先設置的語法規則,動詞 + 名詞短語能構成動詞短語,然后 名詞 + 動詞短語能夠構成一句完整的句子。
成分分析***的要數上下文無關文法 (Context Free Grammar) 及其各種變種,例如概率上下文文法 (Probabilistic Context Free Grammar)。
但是依存文法根據單詞之間的修飾關系將它們連接起來構成一棵樹,樹中的每個節點都代表一個單詞。
子節點的單詞是依賴于父節點的,每條邊標準了依賴關系的類型。
單詞 John 是動詞 sees 的主語,單詞 Bill 是動詞 sees 的賓語。
成分分析的缺點是搜索空間太大,構建樹的時間往往和可供選擇的節點的數目相關,成分分析需要在計算過程中不斷構建新的節點,而依存分析不需要構建新的節點。自然語言中有歧義,例如上下文無關文法中有規則「C <- AB」,「D <- AB」, 那么在計算 AB 應該合成什么節點的時候就出現了兩種選擇,多種歧義組合在一起,使成分分析的搜索空間爆炸增長,必須設計一些算法進行剪枝等操作。而依存分析不會去創建節點,因此沒有這些問題。但是成分分析中保存的信息比依存分析更加多一點,因此可以直接通過一些確定的規則將成分的樹轉化成依存樹。
句法分析算法
依存文法樹的構建我們可以看成是一個狀態轉換的序列。當前的狀態包括三部分,s 為當前的棧,b 為剩余未解析的詞的數組,以及一個依存關系的集合 A。初始的狀態是
s=[ROOT], b=[w_1,...,w_n], A=∅ 。終止的狀態是 b 為空。S 只有一個節點 ROOT , 解析出來的樹就是集合 A 。定義 s_i 為棧頂第 i 個節點。b_i 為第 i 個未解析的詞。可以定義如下的狀態轉移:
- LEFT-ARC(l): 添加一個 s_1—>s_2 的標記為 l 的依賴關系,并且將 s_2 從棧里面移除。
- RIGHT-ARC(l): 添加一個 s_2—>s_1 的標記為 l 的依賴關系,并且將 s_1 從棧里面移除。
- SHIFT: 將 b_1 從未解析詞的數組中移出,放入棧。
假設我們需要解析句子「He wants a Mac.」.
解析的過程如下:
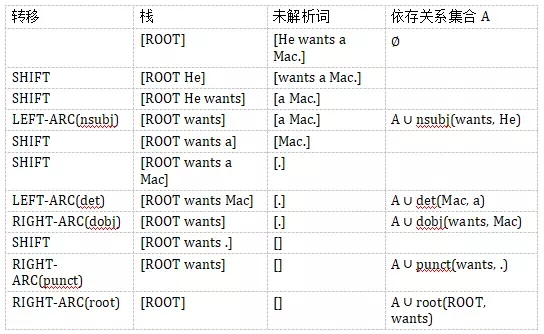
最終得到樹
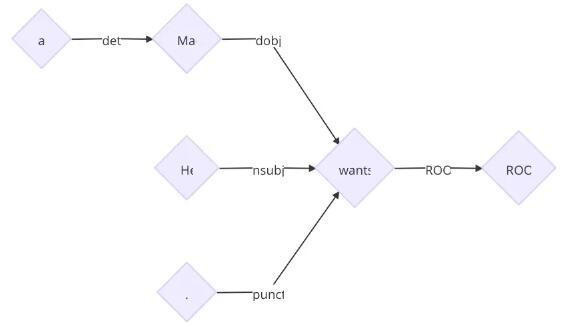
在每個狀態下,我們都有很多可選的轉移。關于如何選出正確的轉移,一般有貪心或者搜索兩種策略。目前的結果表明,盡管貪心比搜索的結果稍微差一點,但是解析的速度快非常多,因此,日常使用基本采用貪心算法。
傳統解析算法的困境
傳統的解析算法需要根據當前的狀態以及預先設置好的規則提取出特征。比如當前棧頂的前兩個詞,當前前幾個未解析的詞等。
但是這些特征有如下問題:
- 稀疏。這些特征尤其是詞法特征,非常稀疏。依存文法的分析依賴于詞之間的關系,有可能兩個詞距離非常遠,那么僅僅提取棧頂前兩個詞作為特征已經無法滿足需要,必須使用更高維度的特征,一旦維度高,勢必使得特征非常稀疏。
- 不完整。人的經驗是有偏差的,專家概括的特征提取規則,總是不完整的。
- 解析算法的絕大部分時間花費在了提取特征中。據統計百分之九十幾的時間花費是特征提取。
此時便需要神經網絡出場來給我們估計哪個是***的狀態轉移了。
遞歸神經網絡 (Recursive Neural Network)
詞嵌入是將單詞表示成低維的稠密的實數向量。自從詞向量技術的提出,到目前為止已經有很多方法來得到句法和語義方面的向量表示,這種技術在 NLP 領域發揮著重要的作用。
如何用稠密的向量表示短語,這是使用詞向量的一個難題。在成分分析中,業界使用遞歸神經網絡 (Recursive Neural Network, RNN) 來解決這個問題。RNN 是一種通用的模型,用來對句子進行建模。句子的語法樹中的左右子節點通過一層線性神經網絡結合起來,根節點的這層神經網絡的參數就表示整句句子。RNN 能夠給語法樹中的所有葉子節點一個固定長度的向量表示,然后遞歸地給中間節點建立向量的表示。
假設我們的語法二叉樹是 p_2—>ap_1 , p_1—>bc ,即 p_2 有子節點a、p_1,p_1 有子節點 b、c 。那么節點表示成
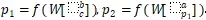
其中 W 是 RNN 的參數矩陣。為了計算一個父節點是否合理,我們可以用一個線性層來打分, score(p_i)=vp_i 。v是需要被訓練的參數向量。在構建樹的過程中,我們采用這種方法來評估各種可能的構建,選出***的構建。
基于神經網絡的依存解析
但是 RNN 只能處理二元的組合,不適合依存分析。因為依存分析的某個節點可能會有非常多的子節點。于是有學者提出用遞歸卷積神經網絡 (Recursive Convolutional Neural Network, RCNN) 來解決這個問題。通過使用 RCNN,我們能夠捕捉到單詞和短語的句法和組合語義的表示。RCNN 的架構能夠處理任意 k 分叉的解析樹。RCNN 是一個通用的架構,不僅能夠用于依存分析,還能對于文章的語義進行建模,將任意長度的文本轉化成固定長度的向量。
1. RCNN 單元
對于依存樹上的每個節點,我們用一個 RCNN 單元來表示改節點與其子節點之間的關系,然后用一層 Pooling 層來獲得***信息量的表示。每個 RCNN 單元又是其父節點的 RCNN 單元的輸入。
下圖展示的是 RCNN 如何來表示短語「He wants a Mac」。
- graph LR
- a{"W(a)"} --> RCNN_UNit_mac[RCNN UNit]
- mac{"W(mac)"} --> RCNN_UNit_mac[RCNN Unit]
- RCNN_UNit_mac --> X_mac{"X(mac)"}
- He{"W(He)"} --> RCNN_UNit_wants["RCNN Unit"]
- wants{"W(wants)"} --> RCNN_UNit_wants
- X_mac --> RCNN_UNit_wants
- P{"W(.)"} --> RCNN_UNit_wants
- RCNN_UNit_wants --> X_wants{"X(wants)"}
- X_wants --> RCNN_Unit_root["RCNN Unit"]
- root{"W(root)"} --> RCNN_Unit_root
- RCNN_Unit_root --> X_root{"X(root)"}
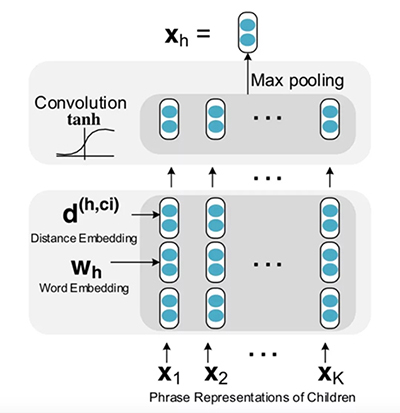
RCNN 單元內部結構如下圖所示:
2. RCNN 單元的構建
- 首先對于每個詞,我們需要將其轉換成向量。這一步一開始可以用已經訓練好的向量,然后在訓練的時候根據反向傳播來進行更新。
- 距離嵌入 (Distance Embedding),除了詞需要嵌入,我們還需要將一個詞和該詞的子節點之間的距離進行編碼。很直覺的是距離近的詞更有可能發生修飾關系。例如上面的例子中,Mac 到 a 的距離是-1,到 wants 的距離是 -2。距離嵌入編碼了子樹的更多信息。
- ***將詞向量和距離向量作為卷積層的輸入。
與一般的解析樹不同,依存分析的樹的每個節點都有兩個向量表示。一個是該節點的單詞的詞向量表示w,另一個是該節點的短語向量表示x。
對于父節點 h,以及某個子節點 c_i,用卷積隱層來計算他們組合起來的表示向量
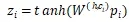
其中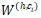 是組合矩陣,
是組合矩陣,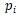 是
是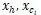 以及距離嵌入
以及距離嵌入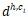 連接起來的向量。tanh是用來當做激發層。
連接起來的向量。tanh是用來當做激發層。
在計算卷積后,對于有 K 個子節點的節點而言,我們得到 K 個向量
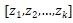
對于 Z 的每一行我們用 Max Pooling 選出最有用的信息。
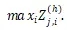
最終得到了該短語的向量表示。
得到向量表示后,計算哪個子樹更加合理,這時就也可以用線性層來打分了。
3. 訓練
對于 RCNN 可以用***間距的標準來訓練。我們選取打分***的解析樹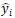 和給定的標準解析樹
和給定的標準解析樹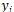 。定義兩棵樹之間的距離
。定義兩棵樹之間的距離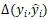 為樹中依賴標記不一致的節點的數目。損失函數就是
為樹中依賴標記不一致的節點的數目。損失函數就是
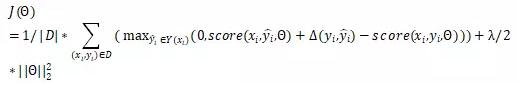
其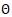 是神經網絡的參數,D是訓練集,score如前面的定義,采用
是神經網絡的參數,D是訓練集,score如前面的定義,采用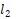 正則項
正則項
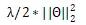
最小化損失的時候,正確的樹的打分被提高,錯誤的樹的打分被降低。
實體識別
在使用依存分析得到解析樹后,我們就能從樹中提取出任意我們想要的短語。
比如我們想要提取出「wants sth」的短語。就可以用如下的算法得到。
- def want_phrase(sentence):
- result = defaultdict(list)
- for token in sentence: # 遍歷所有的token
- if token.head.lemma == 'want' and token.dep == dobj:
- # 如果當前token的依賴指向want及其變形,而且依賴的關系是dobj。那么這是潛在的目標短語
- result[token.head].append(token)
- for token in sentence: # 遍歷所有的token
- if token.head in result and token.text == "n't" and token.dep == neg:
- # 如果當前的token 是 n't, 依賴指向的詞在潛在的目標短語中,而且依賴關系是neg,其實表示的意思是不想要,因此需要從目標短語的集合中剔除。
- del result[token.head] # 這是不喜歡的情況
- return result
結語
本文介紹了如何在傳統的解析算法中用上深度學習的技術。在實踐中,深度學習減少了數據工程師大量的編碼特征的時間,而且效果比人工提取特征好很多。在解析算法中應用神經網絡是一個非常有前景的方向。
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】