













CV內卷!心理學家學會人臉識別,訓練600萬視頻區分世界各地表情
全球各地的人微笑或難過都是一個表情嗎?
人們面部表情具有一致性似乎是合理的,舉例來說,無論一個人是來自巴西、印度還是加拿大,他們看到親密朋友時的微笑,或者看到煙花表演時的激動神情,看起來基本上是一樣的。
但這真的合理嗎?這些面部表情和跨越地域的相關背景之間的聯系真的普遍嗎?在不同文化背景下,人們的微笑或皺眉會告訴我們人們是如何相互聯系的,這兩種情況有什么相似或不同之處呢?
科學家們試圖回答這些問題,并揭示人們在多大程度上跨越文化和地理,往往使用調查為基礎的研究,但這種研究嚴重依賴當地語言、道德規范和價值觀。并且這樣的研究是不可擴展的,常常以小樣本和不一致的結果告終。
與基于調查的研究相比,研究面部運動模式可以更直接地理解表達人類的行為。
但是,分析面部表情在日常生活中的實際使用需要研究人員通過數百萬小時的真實世界的連續鏡頭,這項工作極為繁瑣并且需要大量的人工工作。
此外,面部表情及其展現的背景是復雜的,需要大量的樣本才能得出統計學上可靠的結論。
雖然現有的研究已經對特定情境下面部表情的普遍性問題產生了不同的答案,但是使用機器學習技術來擴展研究也許能提供不同的、更清晰的答案。
2019年在《Nature》上發表的Sixteen facial expressions occur in similar contexts worldwide一文中,是第一次、大規模的、全球范圍內的面部表情在日常生活中實際使用情況的分析研究,利用深層神經網絡擴大表情分析。
論文中共使用來自144個國家的600萬個公開視頻數據集,分析了人們使用各種面部表情的背景,并證明了面部行為中豐富的細微差別,包括微妙的表情,在世界各地類似的社交場合中都有使用。

深度神經網絡測量面部表情面部表情不是靜態的。當一個人看另一個人的表情時,起初看起來可能是憤怒,但結果可能是敬畏、驚訝或是困惑,不同的表情解釋取決于一個人的面部表情所呈現的動態效果。
因此,建立一個神經網絡來理解面部表情的挑戰在于,它必須在其時間上下文(temporal context)中解釋這種表情。訓練這樣一個系統需要一個大型的、多樣化和跨文化的視頻數據集,同時還需要充分解釋的表情含義。
為了建立數據集,標注人員手動搜索廣泛的公開視頻集,以確定那些可能包含涵蓋我們預先選擇的表情類別。
為了確保視頻與它們所代表的區域相匹配,在視頻選擇中優先選擇那些包含原始地理位置的視頻。
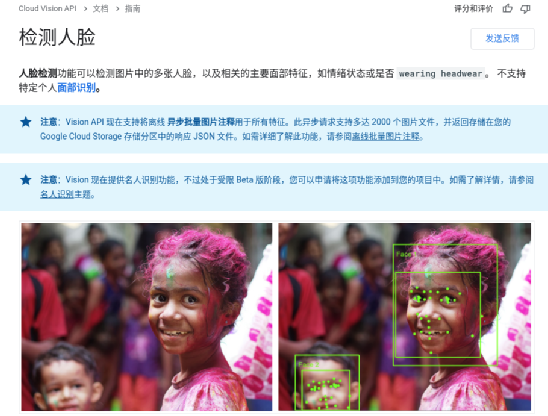
視頻中的人臉是通過一個類似于谷歌云端人臉檢測 API 的深度卷積神經網絡識別系統發現的,該系統使用一種基于傳統光流(optical flow)的方法在視頻剪輯過程中跟蹤人臉。
使用一個類似于 Google 眾包平臺 的界面,如果在剪輯過程中的任何一點出現了面部表情,那么注釋者就會在28個不同的類別中標記它們。
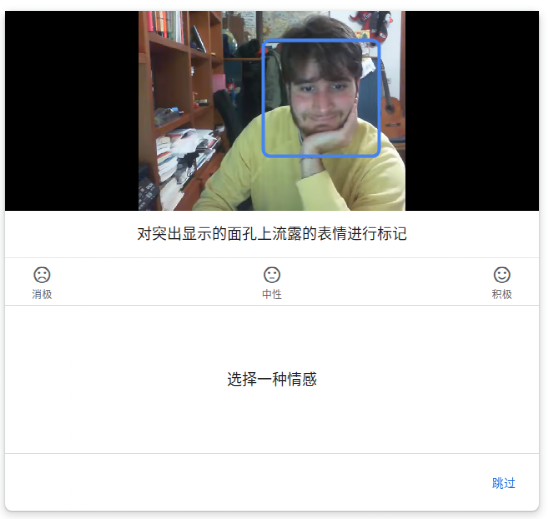
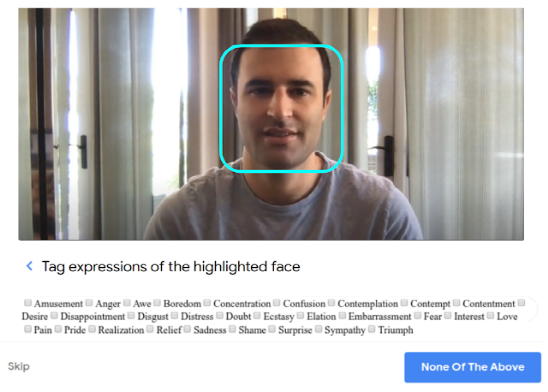
因為目標是取樣一個普通人如何理解一個表情,所以標注人員沒有得到指導或培訓,也沒有提供示例表情或是標注的定義。
文中討論額外的實驗來評估從這些注釋中訓練出來的模型是否有偏差。
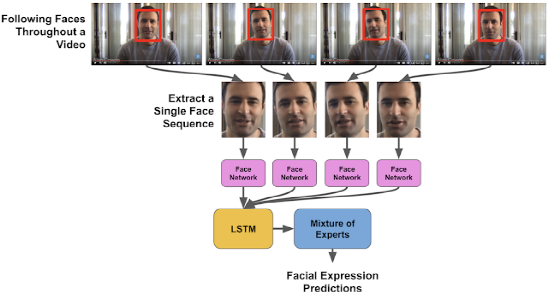
人臉檢測算法在整個視頻中建立了每個人臉的位置序列。然后,我們使用一個預先訓練的初始網絡來提取特征,從臉上找到代表面部表情的最突出的一個部位。
然后,這些特征被輸入一個長期短期記憶網絡(LSTM)中 ,它能夠模擬面部表情隨著時間的推移如何演變的遞歸神經網絡,并且能夠記住過去突出的信息。
為了確保模型在一系列人口統計學群體中做出一致的預測,我們在一個現有的數據集上評估了模型的公平性,這個數據集是使用相似的面部表情標簽構建的,目標是16種表情中表現最好的一種。
該模型的表現在所有類型人口組代表的評價數據集中表現了其一致性,也表明模型訓練帶注釋的面部表情存在不可測量的偏見。該模型對1500張圖片中的16種面部表情進行了注釋。
為了理解數以百萬計的視頻中面部表情的上下文,實驗還測量了視頻中捕獲的表情的前后部分。論文中使用了可以捕獲細粒度內容并自動識別上下文的 神經網絡。
第一個 DNN 是視頻相關的文本特性(標題和描述)與實際的視覺內容(視頻-主題模型)的組合。
第二個 DNN只依賴于文本特征而沒有任何視覺信息(文本-主題模型)。
這些模型預測了上萬個描述視頻的類別標簽,在這個實驗中,這些模型能夠識別數百個獨特的情境(例如,婚禮,體育賽事,或煙花)來展示分析數據的多樣性。
文中的第一個實驗中,研究人員分析了300萬個手機拍攝的公共視頻,手機拍攝的視頻更可能包含自然的表情。
然后將視頻中出現的面部表情與來自視頻主題模型的上下文注釋相關聯,發現16種面部表情與日常社會環境有著不同的聯系,這些聯系在世界各地都是一致的。例如,歡樂的表情和惡作劇共同出現的概率更大; 激動的表情和煙花也更配; 勝利的表情也經常出現在體育賽事中。
這些結果對于討論面部表情中,心理相關的場景對表情的使用有很強的暗示作用,比其他因素如那些個人、文化或社會所特有的因素更相關。
第二個實驗分析了300萬個單獨的視頻,這次使用用文本主題模型注釋了上下文。結果證實了第一個實驗中的發現并不是由視頻中面部表情對視頻主題模型注釋的微妙影響所驅動的。換句話說,這個實驗證實了第一個實驗得出的結論,即視頻主題模型在計算其內容標簽時可能隱含著面部表情的因素。
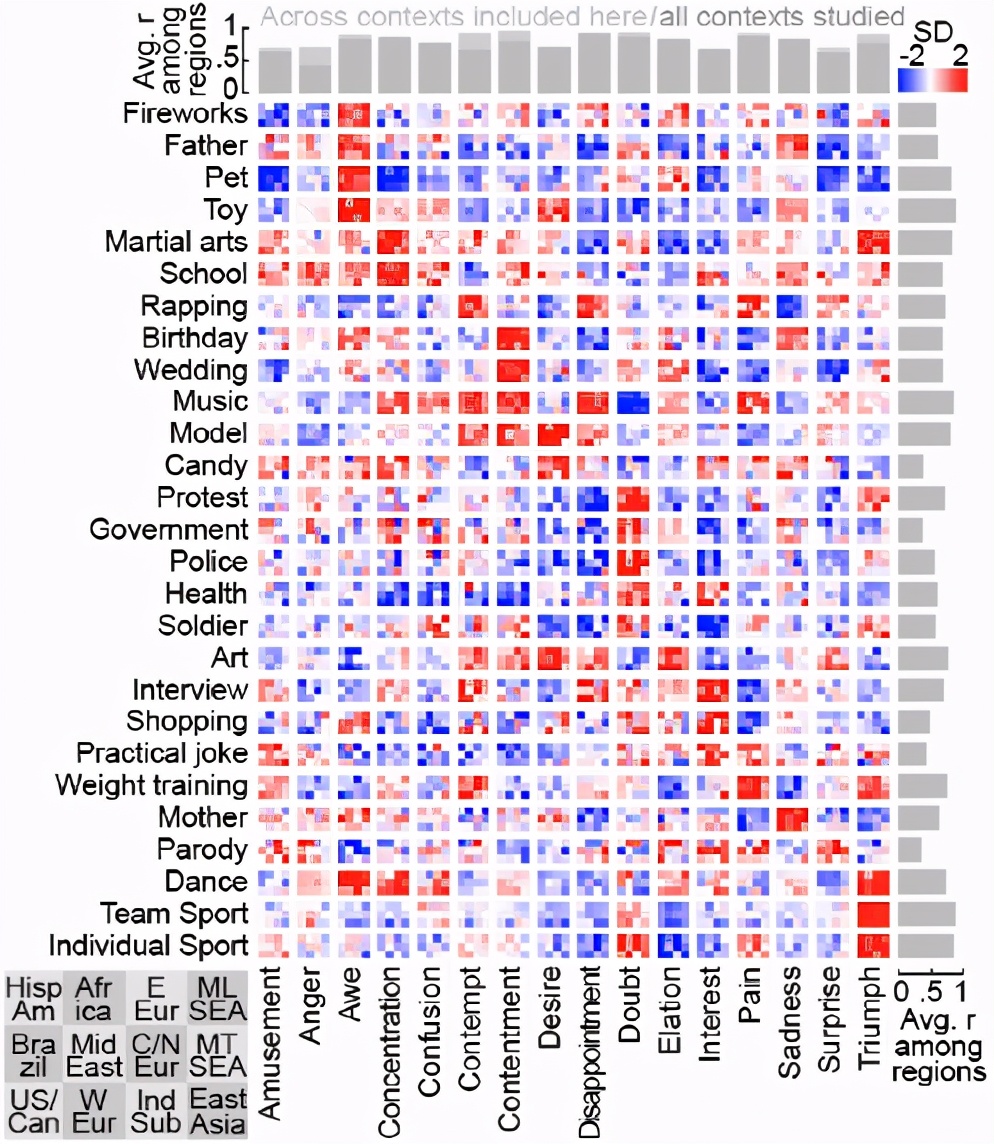
在這兩個實驗中,表情和語境之間的相關性在不同的文化中似乎都得到了很好的驗證。為了準確地量化研究的12個不同世界區域的表達式和上下文之間的關聯是多么相似,研究人員計算了每一對區域之間的二階相關性。這些相關性確定了每個區域中不同表情和上下文之間的關系,然后將它們與其他區域進行比較。
最后結論,在每個地區發現的70% 的情境表情關聯在世界范圍是共享的。
機器學習使研究人員能夠分析世界各地數以百萬計的視頻,并發現支持面部表情在跨文化的相似環境中被保留到一定程度這一假設的證據。
研究結果也為文化差異留下了空間,盡管面部表情和上下文之間的相關性在世界范圍內有70% 的一致性,但是在不同地區之間的相關性只有30% 。相鄰世界地區的面部表情和語境之間的關聯通常比相距遙遠的世界地區的關聯更為相似,這表明人類文化的地理傳播也可能在面部表情的意義上發揮作用。
這項工作表明,機器學習能夠更好地了解自己,并確定跨文化的共同溝通要素。神經網絡等工具使我們有機會為科學發現提供大量不同的數據,使我們對統計結論更有信心。















