













手把手教你設計大數據流水線
在數據架構中,數據流水線一般以數據為起點,以洞見為終點。如何從起點到終點,取決于一系列的因素。圖1展示了一個數據架構下的數據流水線。
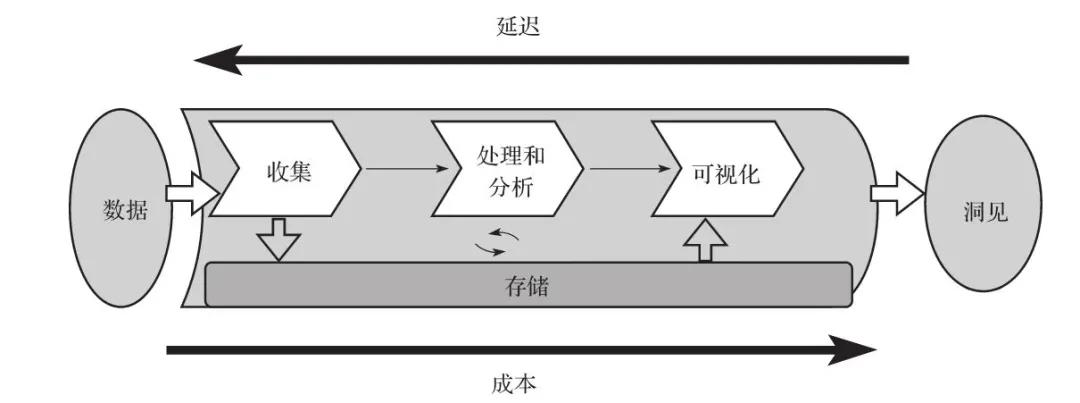
圖1 大數據架構設計中的數據流水線
如圖1所示,大數據流水線的標準工作流程包括以下步驟:
1)通過合適的工具收集數據(攝取)。
2)持久化存儲數據。
3)數據處理或分析。從存儲中獲取數據,對其進行操作,然后將處理后的數據再次存儲。
4)數據被其他處理/分析工具使用,或者被同一工具再次處理,從數據中獲得進一步的結果。
5)為了使結果對業務用戶有用,使用商業智能(BI)工具將結果可視化,或者將結果輸入機器學習算法中進行預測。
6)一旦將合理的結果呈現給用戶,這就為他們提供了對數據的洞見,然后他們可以采用這些數據進行進一步的業務決策。
你在流水線中部署的工具決定了獲得結果的時間,也就是從數據被創建到能從中獲得洞見之間的延遲。在考慮延遲的同時,設計數據架構的最佳方法是確定如何平衡吞吐量與成本,因為更高的性能和隨之而來的低延遲通常會導致更高的成本。
大數據處理流水線設計
許多大數據架構所犯的關鍵性錯誤之一是,試圖用一個工具包辦數據流水線的多個階段的數據處理。用一個服務器機群來端到端地處理從數據存儲、轉換到數據可視化的整個流水線可能是最簡單,但它也是最容易發生故障的。這種緊耦合的大數據架構通常不能根據你的需求提供吞吐量和成本的最佳平衡。
建議數據架構師對流水線進行解耦,特別是將存儲和處理分為多個階段,這樣做有很多好處,包括提高容錯能力。例如,如果在第二輪處理中出了問題,或者專門用于處理該任務的硬件出現故障,不必從流水線的起點重新開始,系統可以從第二個存儲階段恢復。將存儲與各個處理層解耦,使你有能力對多個數據存儲進行讀寫。
圖2說明了設計大數據架構流水線時需要考慮的各種工具和流程。
為大數據架構進行工具選型時,應該考慮以下幾點:
- 數據結構。
- 最大可接受的延遲。
- 最低可接受的吞吐量。
- 系統終端用戶的典型訪問模式。
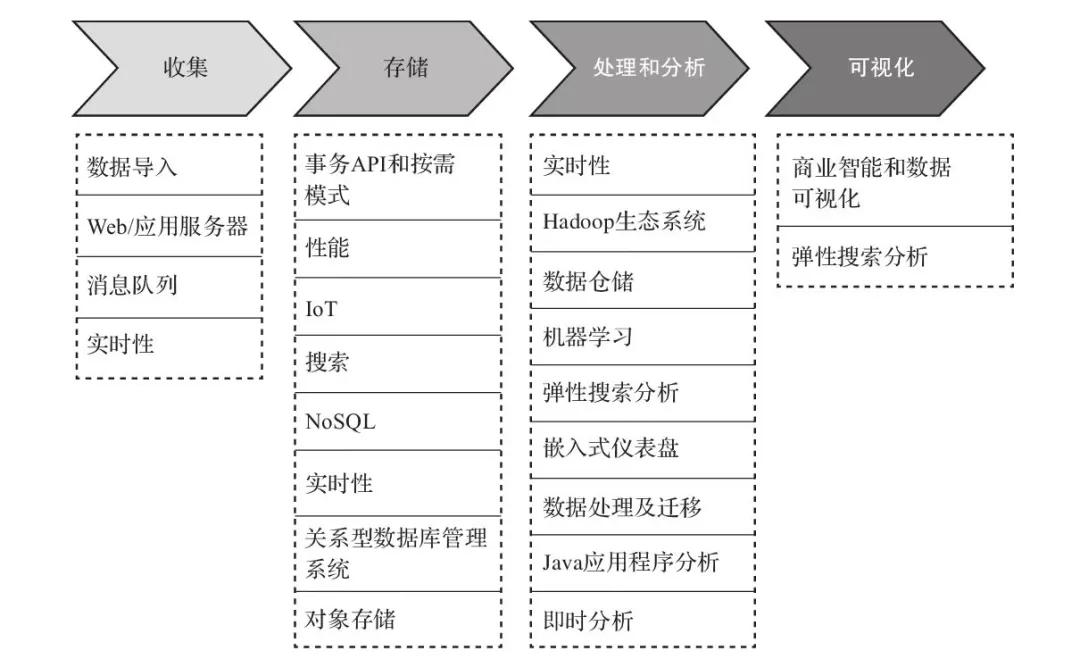
圖2 大數據架構設計中的工具與流程
數據結構會影響數據處理工具以及存儲位置的選擇。數據的順序及要存儲和檢索的數據對象的大小也是必不可少要考慮的因素。獲得結果的時間取決于解決方案如何權衡延遲、吞吐量和成本。
用戶訪問模式是另一個需要考慮的重要因素。有些作業需要定期快速連接許多相關的表,有些作業則需要每天或按更低頻率使用存儲的數據。有些作業需要比較來自各種數據源的數據,而有些作業只需要從一個非結構化表中提取數據。了解終端用戶最常使用數據的方式將有助于確定大數據架構的廣度和深度。接下來,我們將更加深入地探討大數據架構中的每個流程和涉及的工具。
本文摘編自《解決方案架構師修煉之道》,經出版方授權發布。(ISBN:9787111694441)轉載請保留文章出處。



















