全面取代Llama 2!Baichuan 2自曝史上最全訓(xùn)練細(xì)節(jié)
在國內(nèi),Llama的時(shí)代,已經(jīng)過去了。
9月6日,百川智能宣布正式開源Baichuan 2系列大模型,包含7B、13B的Base和Chat版本,并提供了Chat版本的4bits量化,均為免費(fèi)商用。

下載鏈接:https://github.com/baichuan-inc/Baichuan2
在所有主流中英文通用榜單上,Baichuan 2全面領(lǐng)先Llama 2,而Baichuan2-13B更是秒殺所有同尺寸開源模型。毫不夸張地說,Baichuan2-13B是目前同尺寸性能最好的中文開源模型。
而在過去一個(gè)月里,Baichuan系列的下載量在Hugging Face等開源社區(qū)已經(jīng)超過了347萬次,是當(dāng)月下載量最高的開源大模型,總下載量已經(jīng)突破500萬次。


Llama 2,已經(jīng)不需要了
相比之下,國外的當(dāng)紅炸子雞Llama 2,就可以和我們說拜拜了。
千模大戰(zhàn)過后,大模型已經(jīng)進(jìn)入了「安卓時(shí)刻」。現(xiàn)在看來,最有希望替代Llama 2的國產(chǎn)大模型,就是Baichuan 2。
原因其實(shí)很簡單,一方面Baichuan 2系列大模型在性能上,不僅以絕對優(yōu)勢領(lǐng)先Llama 2,而且大幅度優(yōu)于同尺寸的競品。
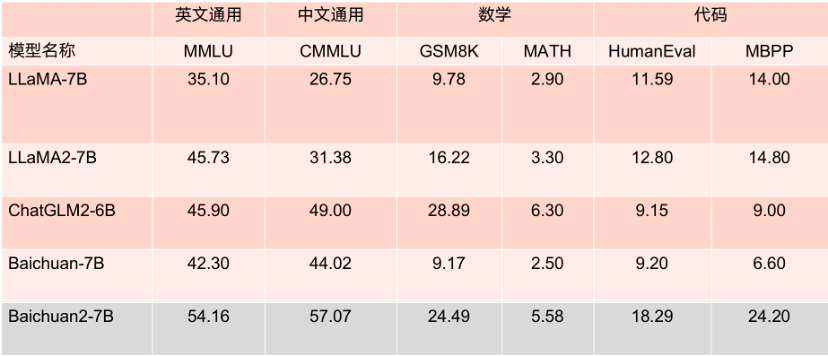
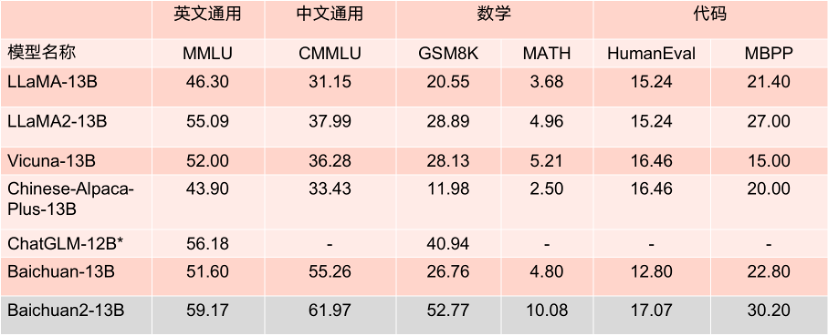
另一方面,在Meta的商用協(xié)議中,實(shí)際上并不允許開放Llama模型在中文社區(qū)的商用;而Baichuan系列大模型目前是全面開源商用的。

Llama 2商業(yè)協(xié)議明確表示不允許英文以外的商業(yè)
中文開源第一
作為中文開源大模型的第一,百川大模型面對LLM經(jīng)典難題的表現(xiàn),也讓人眼前一亮。
對于博大精深的漢語,具備精準(zhǔn)語義理解能力的Baichuan 2,可以充分理解其中的精妙。
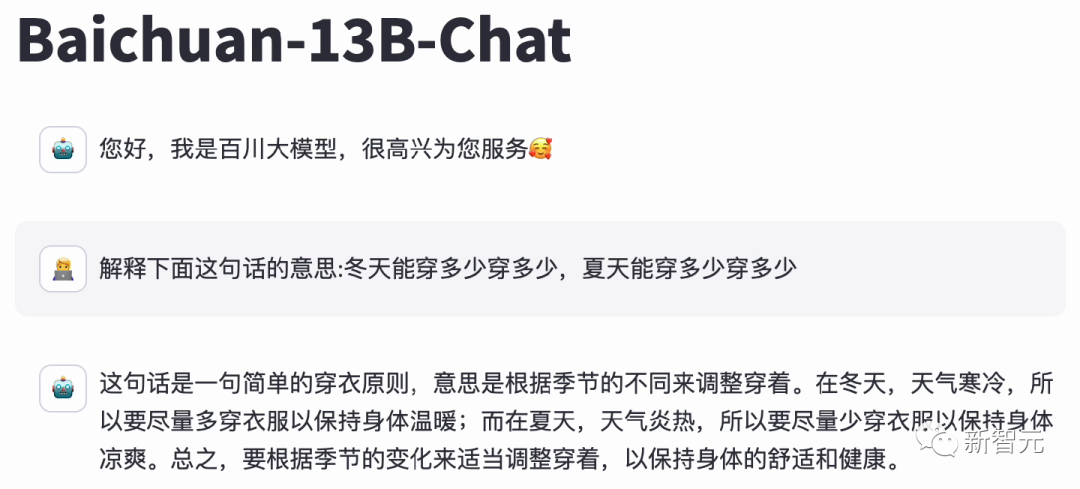
而并不擅長中文的Llama 2 13B,只是說了一堆無用的廢話。

在考驗(yàn)推理能力的代碼生成方面,Baichuan 2能做到足夠的精細(xì)化,并且可用率已經(jīng)達(dá)到了行業(yè)領(lǐng)先水平。

對于這道題,Llama 2也可以搞定,但默認(rèn)只會(huì)用英文進(jìn)行回復(fù)。

難度更大的多輪對話,讓無數(shù)大模型折戟。

在這方面,百川大模型可以說是遙遙領(lǐng)先,能夠輕松完成各種復(fù)雜的指令跟隨。

就連難倒GPT-4的推理題,百川大模型都不在話下。


模型評測
除了剛剛這些真實(shí)場景的評測外,Baichuan 2在多個(gè)權(quán)威的中文、英文和多語言的通用以及專業(yè)領(lǐng)域的基準(zhǔn)測試中,都取得了同等規(guī)模最佳的效果,而Llama 2則是全面落敗。
對于通用領(lǐng)域,評測采用的基準(zhǔn)為:中文基礎(chǔ)模型評測數(shù)據(jù)集C-Eval、主流英文評測數(shù)據(jù)集MMLU、評估知識(shí)和推理能力的中文基準(zhǔn)CMMLU、評估語言和邏輯推理能力的數(shù)據(jù)集Gaokao、評估認(rèn)知和解決問題等通用能力的AGIEval,以及挑戰(zhàn)性任務(wù)Big-Bench的子集BBH。

在法律領(lǐng)域,采用的是基于中國國家司法考試的JEC-QA數(shù)據(jù)集。在醫(yī)療領(lǐng)域,除了通用領(lǐng)域數(shù)據(jù)集中醫(yī)學(xué)相關(guān)的問題外,還有MedQA和MedMCQA。

數(shù)學(xué)領(lǐng)域?yàn)镚SM8K和MATH數(shù)據(jù)集;代碼領(lǐng)域?yàn)镠umanEval和MBPP數(shù)據(jù)集。

最后,在多語言能力方面,則采用了源于新聞、旅游指南和書籍等多個(gè)不同領(lǐng)域的數(shù)據(jù)集Flores-101,它包含英語在內(nèi)的101種語言。

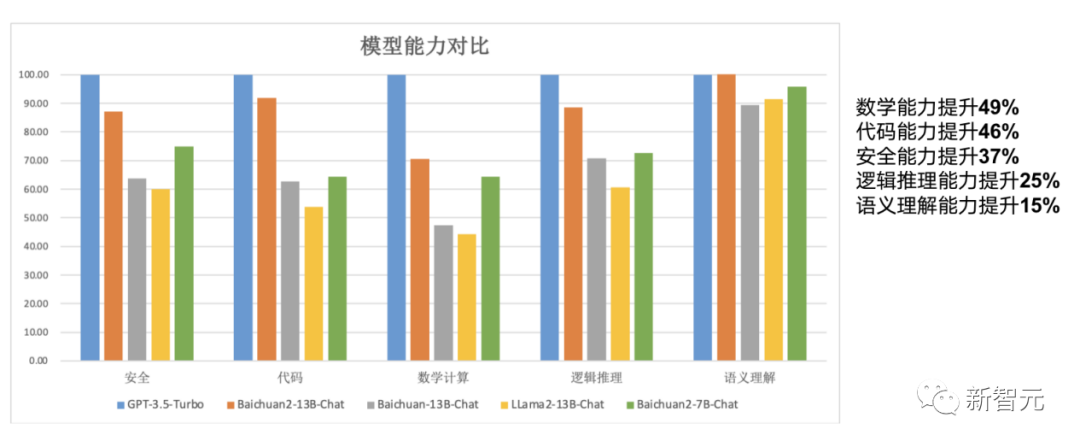
總結(jié)來說,Baichuan 2系列不僅繼承了上一代良好的生成與創(chuàng)作能力,流暢的多輪對話能力以及部署門檻較低等眾多特性,而且在數(shù)學(xué)、代碼、安全、邏輯推理、語義理解等能力有顯著提升。
其中,Baichuan2-13B-Base相比上一代13B模型,數(shù)學(xué)能力提升49%,代碼能力提升46%,安全能力提升37%,邏輯推理能力提升25%,語義理解能力提升15%。
數(shù)據(jù)
Baichuan 2系列大模型之所以能實(shí)現(xiàn)如此傲人的成績,其中一個(gè)原因便是,訓(xùn)練語料規(guī)模大、覆蓋全,且質(zhì)量優(yōu)。
在數(shù)據(jù)獲取上,百川團(tuán)隊(duì)主要從網(wǎng)頁、書籍、研究論文、代碼庫等豐富的數(shù)據(jù)源采集信息,覆蓋了科技、商業(yè)、娛樂等各個(gè)領(lǐng)域。
總計(jì)有2.6TB token規(guī)模的數(shù)據(jù)集。
與此同時(shí),數(shù)據(jù)集中也加入了多語言的支持,包括中文、英文、西班牙語、法語等數(shù)十種語言。

Baichuan 2訓(xùn)練數(shù)據(jù)不同種類分布
那么,優(yōu)秀的數(shù)據(jù)質(zhì)量獲取是如何實(shí)現(xiàn)?
作為一家有搜索基因的公司,百川智能借鑒了之前在搜索領(lǐng)域的經(jīng)驗(yàn),將重點(diǎn)放在了數(shù)據(jù)頻率和質(zhì)量上。
一方面,通過建立一個(gè)大規(guī)模「重復(fù)數(shù)據(jù)刪除和聚類系統(tǒng)」,能夠在數(shù)小時(shí)內(nèi),實(shí)現(xiàn)對千億級數(shù)據(jù)的快速清洗和去重。
另一方面,數(shù)據(jù)清洗時(shí)還采用了多粒度內(nèi)容質(zhì)量打分,不僅參考了篇章級、段落級、句子級的評價(jià),還參考了搜索中對內(nèi)容評價(jià)的精選。
通過細(xì)粒度采樣,大幅提升了模型生成質(zhì)量,尤其是在中文領(lǐng)域。
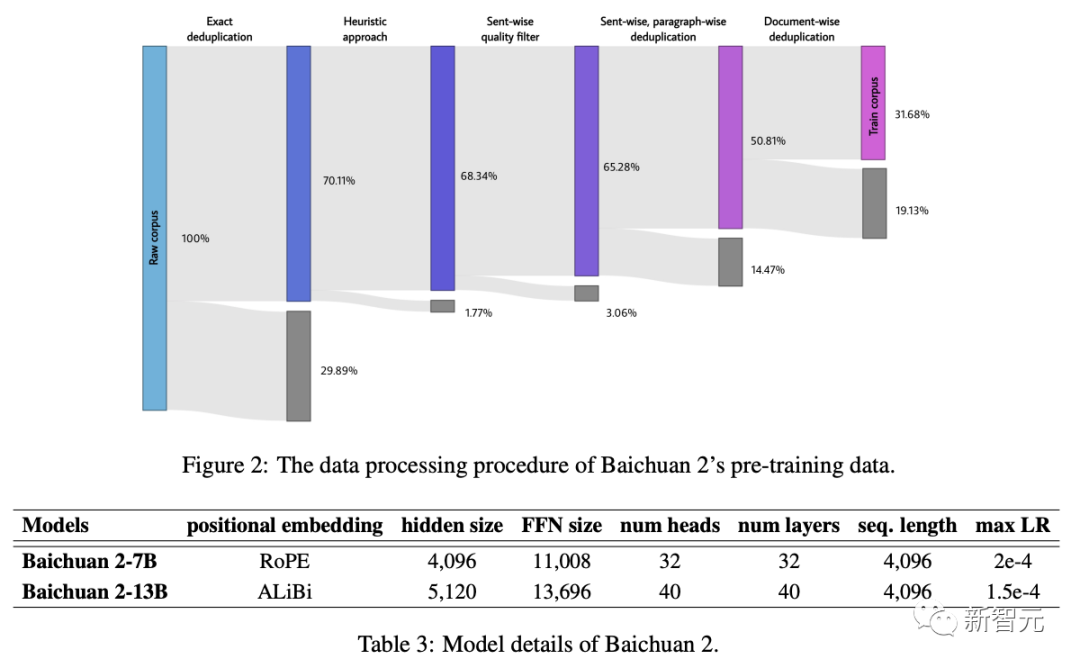
不同數(shù)據(jù)處理階段的訓(xùn)練數(shù)據(jù)大小
訓(xùn)練
數(shù)據(jù)準(zhǔn)備完成后,接下來就進(jìn)入大模型最重要的階段——訓(xùn)練。
百川團(tuán)隊(duì)使用AdamW優(yōu)化器,BFloat16混合精度對模型進(jìn)行了訓(xùn)練。
為了穩(wěn)定訓(xùn)練過程,提高模型性能,研究還采用了NormHead,對輸出embedding進(jìn)行歸一化處理。
另外,在訓(xùn)練期間,百川團(tuán)隊(duì)還發(fā)現(xiàn)LLM的對數(shù)值可能會(huì)變得非常大,由此引入Max-z loss來穩(wěn)定訓(xùn)練,讓模型推理對超參數(shù)更加穩(wěn)健。
如下圖,可以看到,Baichuan2-7B/13B的損失曲線在持續(xù)降低。

以往研究表明,模型的性能隨著參數(shù)規(guī)模的擴(kuò)大呈現(xiàn)出一定的可預(yù)測性,也就是人們常說的scaling law。
在訓(xùn)練數(shù)十億參數(shù)的大型語言模型之前,百川智能預(yù)訓(xùn)練了從10M到30B參數(shù)的模型,總計(jì)token規(guī)模達(dá)1萬億。
通過將冪律項(xiàng)擬合到給定訓(xùn)練浮點(diǎn)運(yùn)算次數(shù)的損失中,可以預(yù)測在2.6萬億token上訓(xùn)練Baichuan2-7B和Baichuan2-13B的損失曲線。
如下圖所示,30M、50M、100M等不同參數(shù)規(guī)模的模型曲線都在下降,并且最后能夠線性回歸到一個(gè)值。
這使得,在預(yù)測更大規(guī)模模型的性能時(shí),能夠有一個(gè)較為準(zhǔn)確的估計(jì)。

值得一提的是,這與OpenAI在發(fā)布GPT-4時(shí)的情況類似,只需要萬分之一的訓(xùn)練,可以預(yù)測后面模型的性能。
由此可見,整個(gè)擬合過程,能夠較為精確地預(yù)測模型的損失。
同時(shí),百川基礎(chǔ)設(shè)施的團(tuán)隊(duì)進(jìn)行了大量工作,優(yōu)化了集群性能,使得目前千卡A800集群達(dá)到180TFLOPS訓(xùn)練速度,機(jī)器利用率超過50%,達(dá)到行業(yè)領(lǐng)先水平。
如上,在訓(xùn)練過程中,百川智能模型呈現(xiàn)出了高效、穩(wěn)定、可預(yù)測的能力。
安全
那么,訓(xùn)練后得到的模型,如何確保是安全的呢?百川智能在此也做了很多安全對齊的工作。
在模型訓(xùn)練前,團(tuán)隊(duì)已經(jīng)對整個(gè)數(shù)據(jù)集進(jìn)行了嚴(yán)格的過濾,還策劃了一個(gè)中英文雙語數(shù)據(jù)集,納入了各種正能量的數(shù)據(jù)。
另一方面,百川智能還對模型做了微調(diào)增強(qiáng),安全強(qiáng)化學(xué)習(xí),設(shè)置了6種打擊類型,并進(jìn)行了大量紅藍(lán)對抗訓(xùn)練,能夠提升模型的魯棒性。

在強(qiáng)化學(xué)習(xí)優(yōu)化階段,通過DPO方法可以有效利用少量標(biāo)注數(shù)據(jù),來提升模型對特定漏洞問題的性能。
另外,還采用了結(jié)合有益和無害目標(biāo)的獎(jiǎng)勵(lì)模型,進(jìn)行了PPO安全強(qiáng)化訓(xùn)練,在不降低模型有用性的前提下,顯著增強(qiáng)了系統(tǒng)的安全性。
可以看到,百川智能在模型安全對齊方面也做出很多努力,包括預(yù)訓(xùn)練數(shù)據(jù)加強(qiáng)、安全微調(diào)、安全強(qiáng)化學(xué)習(xí)、引入紅藍(lán)對抗。
Baichuan 2的開源,是真正的開源
對于學(xué)術(shù)界來說,是什么阻礙了對大模型訓(xùn)練的深入研究?
從0到1完整訓(xùn)練一個(gè)模型,成本是極其高昂的,每個(gè)環(huán)節(jié)都需要大量人力、算力的投入。
其中,在大模型的訓(xùn)練上,更是包括了海量的高質(zhì)量數(shù)據(jù)獲取、大規(guī)模訓(xùn)練集群穩(wěn)定訓(xùn)練、模型算法調(diào)優(yōu)等等,失之毫厘,差之千里。
然而,目前大部分的開源模型,只是對外公開了模型權(quán)重,對于訓(xùn)練細(xì)節(jié)卻很少提及。并且,這些模型都是最終版本,甚至還帶著Chat,對學(xué)術(shù)界并不友好。
也是因此,企業(yè)、研究機(jī)構(gòu)、開發(fā)者們,都只能在模型基礎(chǔ)上做有限的微調(diào),很難深入研究。
針對這一點(diǎn),百川智能直接公開了Baichuan 2的技術(shù)報(bào)告,并詳細(xì)介紹了Baichuan 2訓(xùn)練的全過程,包括數(shù)據(jù)處理、模型結(jié)構(gòu)優(yōu)化、Scaling law、過程指標(biāo)等。
更重要的是,百川智能還開源了模型訓(xùn)練從220B到2640B全過程的Check Ponit。
這在國內(nèi)開源生態(tài)尚屬首次!
對于模型訓(xùn)練過程、模型繼續(xù)訓(xùn)練和模型的價(jià)值觀對齊等方面的研究來說,Check Ponit極具價(jià)值。
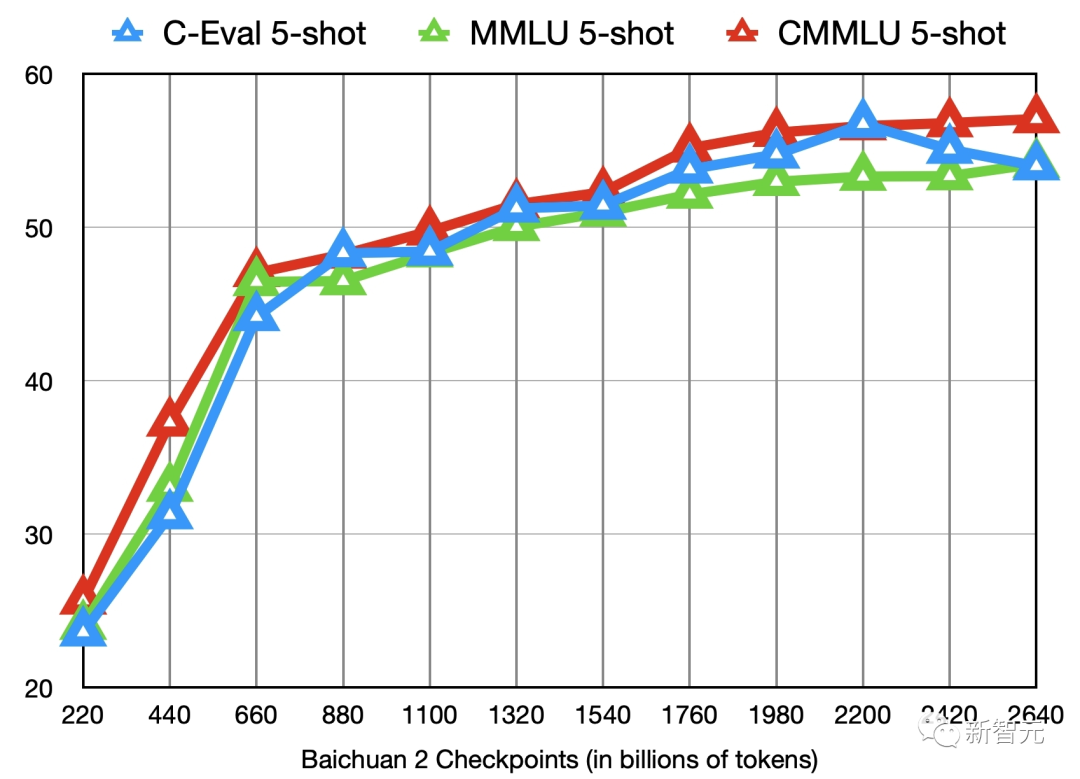
Baichuan 2的11個(gè)中間checkpoints在C-Eval、MMLU、CMMLU三個(gè)benchmark上的效果變化
對此,復(fù)旦大學(xué)計(jì)算科學(xué)技術(shù)學(xué)院教授張奇表示:
Baichuan系列發(fā)布的模型分片,對于研究大模型的本質(zhì)來說有非常大的好處。我們既可以知道它每次的迭代過程,也可以在中間的分片里面做非常多的事情。
而且,相比于那些直接開源最終版,甚至還是Chat版的模型,百川開源得非常干凈,從底座開始就是很干凈的語言模型。
此外,很多的評測都是從單點(diǎn)維度進(jìn)行的,甚至在某些榜單,GPT-4都排到第10了,這其實(shí)沒有任何意義。而百川的評測結(jié)果就非常好。
而從商業(yè)角度看,Baichuan 2模型也是企業(yè)非常好的選擇。
之前免費(fèi)可商用的Llama 2發(fā)布后,許多人認(rèn)為這會(huì)對眾多創(chuàng)業(yè)公司造成打擊,因?yàn)樗梢詽M足低成本、個(gè)性化的需求。
但經(jīng)過仔細(xì)思考就能明白,Llama 2并未改變市場格局。
企業(yè)若是要用模型,即使是微調(diào),也需要花費(fèi)一些成本、精力和時(shí)間。
而如果選一個(gè)性能較弱的模型(尤其是主要基于英文語料的模型),重新訓(xùn)練也是有難度的,成本幾乎跟自己重新去做一個(gè)大模型差不多了。
既然Llama 2不擅長中文,協(xié)議也禁止非英文場景商用化,因此顯而易見,在商用領(lǐng)域,綜合能力更強(qiáng)的開源模型Baichuan 2,幾乎可以說是不二之選。
基于Baichuan 2系列大模型,國內(nèi)研究人員可以進(jìn)行二次開發(fā),快速將技術(shù)融進(jìn)現(xiàn)實(shí)的場景之中。
一言蔽之,Baichuan 2就像是源源不斷地活水,不僅通過盡可能全面的開源來極大地推動(dòng)國內(nèi)大模型的科研進(jìn)展,而且還通過降低國內(nèi)商業(yè)部署門檻讓應(yīng)用創(chuàng)新能夠不斷涌現(xiàn)。