













2024年,端到端自動駕駛在國內是否會有實質性的突破和進展?
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
毫不意外,隨著Tesla V12在北美大范圍推送以及憑借其良好的表現開始獲得越來越多用戶的認同,端到端自動駕駛也成為了自動駕駛行業里大家最為關注的技術方向。最近有機會和很多行業中的一流工程師,產品經理,投資者,媒體人進行了一些交流,發現大家雖然對端到端自動駕駛很感興趣,但甚至在一些對端到端自動駕駛的基本理解上還存在著一些這樣那樣的誤區。作為有幸體驗過國內一線品牌有圖無圖城市功能,同時又體驗過FSD V11和V12兩個版本的人,在這里我想結合自己專業背景和對Tesla FSD常年的進展跟蹤,談幾個現階段大家談及端到端自動駕駛的常見誤區,并給出我自己對于這些問題的解讀。
疑惑一:端到端感知,端到端決策規劃都可以算作是端到端自動駕駛?
首先端到端自動駕駛的定義基本上大家明確了是指從傳感器輸入開始到規劃甚至控制信號輸出(馬斯克所說Photon to Control)中間所有的步驟都是端到端可導,這樣整個系統可以作為一個大模型進行梯度下降的訓練,通過梯度反向傳播可以在模型訓練期間對模型從輸入到輸出之間的全部環節進行參數更新優化,從而能夠針對用戶直接感知到的駕駛決策軌跡,優化整個系統的駕駛行為。而最近一些友商在宣傳端到端的自動駕駛的過程中聲稱自己是端到端感知,或者端到端的決策,但這二者其實我認為都不能算作是端到端的自動駕駛,而只能被稱作純數據驅動的感知和純數據驅動的決策規劃。
甚至有的人將模型出決策,再結合傳統方法來做安全校驗和軌跡優化的混合策略也叫做端到端規劃,另外也有說法認為Tesla V12并不是純粹的模型輸出控制信號,應該也是結合了一些規則方法的混合策略,根據就是http://X.com上的著名Green前段時間發過一條twitter稱在V12技術棧里還是能夠發現規則的代碼。對此我的理解是Green發現的代碼很可能是V12高速技術棧保留的V11版本代碼,因為我們知道目前V12其實只是用端到端替換了原本城市技術棧,高速仍舊會切回V11的方案,因此在解開的代碼中找到一些規則代碼的只言片語并不代表V12是假“端到端”而是找到的很可能是高速的代碼。實際上我們從2022年的AI Day上就可以看出,V11及以前的版本已經是混合方案,因此V12如果不是徹底的模型直出軌跡,那么方案上就和之前的版本沒有什么本質的區別了,如果是這樣V12的性能跳躍性提升又沒辦法合理的解釋了。關于Tesla之前的方案可以參考我的AI Day解讀EatElephant:Tesla AI Day 2022 - 萬字解讀:堪稱自動駕駛春晚,去中心化的研發團隊,野心勃勃的向AI技術公司轉型。
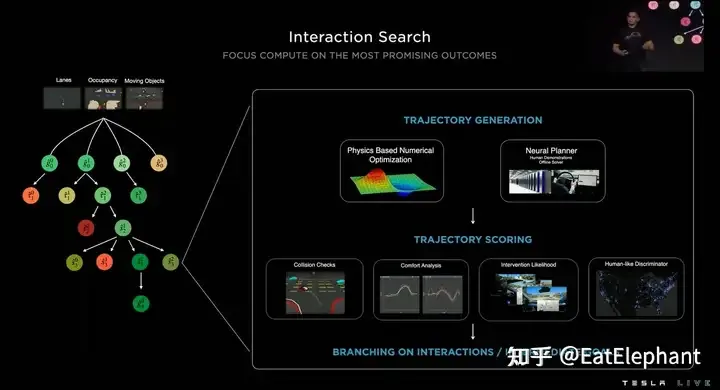
從2022年AI Day上來看,V11已經是混合了NN Planner的規劃方案
總而言之,無論是感知后處理代碼,還是規劃的候選軌跡打分,甚至是安全兜底策略,一旦引入了規則的代碼,有了if else的分支,整個系統的梯度傳遞就會被截斷,這也就損失了端到端系統通過訓練獲得全局優化的最大優勢。
疑惑二:端到端是對之前技術的推倒重來?
另一個常見的誤區是端到端就是推翻了之前積累的技術進行徹底的新技術的革新,并且很多人覺得既然Tesla剛剛實現了端到端自動駕駛系統的用戶推送,那么其他廠商根本不用再在原本感知,預測,規劃的模塊化技術棧上迭代,大家直接進入端到端的系統,反而可以憑借后發優勢快速追上甚至趕超Tesla。確實以一個大模型來完成從傳感器輸入到規劃控制信號的映射是最為徹底的端到端,也很早就有公司嘗試過類似的方法,例如Nvidia的DAVE-2和Wayve等公司就使用了類似的方法。這種徹底的端到端技術確實更接近黑盒,很難進行debug和迭代優化,同時由于傳感器輸入信號如圖像,點云等是非常高緯度的輸入空間,輸出控制信號如方向盤轉角和油門剎車踏板是相對輸入來說非常低維的輸出空間。由高維空間向低維空間的映射是由非常多的可行映射,然而這其中真正對應正確可靠邏輯的映射則只是其中一個映射,也就是說直接進行這樣的端到端訓練非常容易過擬合,導致實車測試完全無法使用。
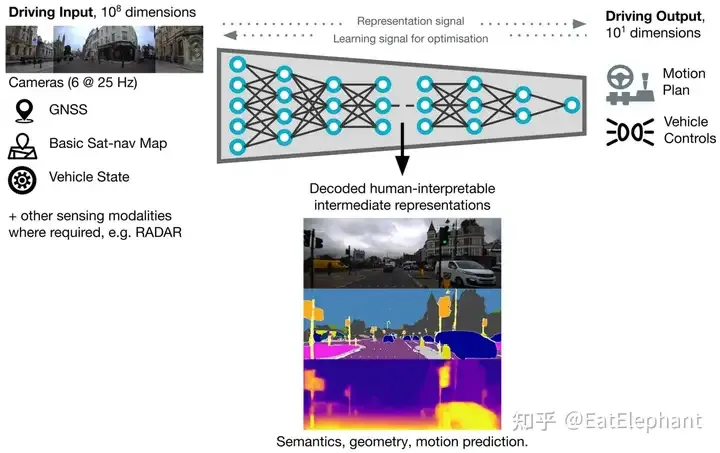
徹底的端到端系統也會使用一些常見的如語義分割,深度估計等輔助任務幫助模型收斂和debug
所以我們實際看到的FSD V12保留了幾乎所有之前的可視化內容,這表明FSD V12是在原本強大的感知的基礎上進行的端到端訓練,從2020年10月開始的FSD迭代并沒有被拋棄,反而是成為了V12堅實的技術基礎。Andrej Karparthy之前也回答過類似問題,他雖然沒有參與V12的研發,但他認為所有之前的技術積累并沒有被拋棄,只是從臺前遷移到了幕后。所以端到端是在原有技術基礎上一步步去掉個部分的規則代碼逐漸實現的端到端可導。
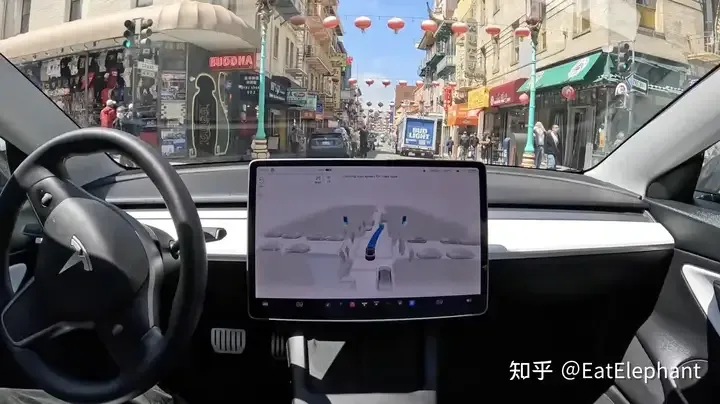
V12保留了FSD幾乎所有的感知,只取消了椎桶等有限的可視化內容
疑惑三:學術Paper中的端到端能否遷移到實際產品中?
UniAD成為2023年CVPR Best Paper無疑代表了學術界對端到端的自動駕駛系統寄予的厚望。從2021年Tesla介紹了其視覺BEV感知技術的創新后,國內學術界在自動駕駛BEV感知方面投入了非常大的熱情,并誕生了一些列研究,推動了BEV方法的性能優化和落地部署,那么端到端是否也能走一條類似的路線,由學術界引領,產業界跟隨從而推動端到端技術在產品上的快速迭代落地呢?我認為是比較難的。首先BEV感知還是一個相對模塊化的技術,更多是算法層面,且入門級性能對數據量的需求沒有那么高,高質量的學術開源數據集Nuscenes的推出為很多BEV研究提供了便利的前置條件,在Nuscenes上迭代的BEV感知方案雖然無法達到產品級性能要求,但是作為概念驗證和模型選型,是具有很大借鑒價值的。然而學術界缺乏大規模的端到端可用數據。目前最大規模的Nuplan數據集包含了4個城市1200小時的實車采集數據,然而在2023年的一次財報會議上,Musk表示對于端到端的自動駕駛“訓練了100萬個視頻case,勉強可以工作;200萬個,稍好一些;300萬個,就會感到Wow;到了1000萬個,它的表現就變得難以置信了”。Tesla的Autopilot回傳數據普遍認為是1min的片段,那么入門級別的100w視頻case大概就是16000小時,比最大的學術數據集至少多一個數量級以上,這里還是要注意nuplan是連續采集數據,因此在數據的分布和多樣性上有著致命的缺陷,絕大多數數據都是簡單場景,這也就意味著使用nuplan這樣的學術數據集甚至無法獲得一個能夠勉強上車的版本。
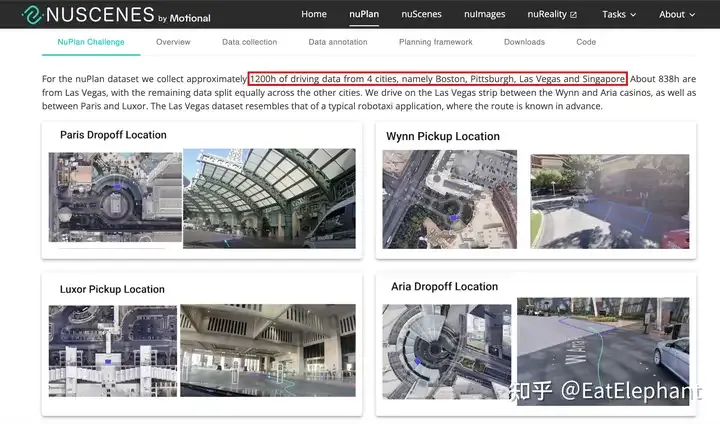
Nuplan數據集已經是非常巨大規模的學術數據集,然而作為端到端方案的探索可能還遠遠不夠
于是我們看到包括UniAD在內的絕大多數端到端自動駕駛方案都無法實車運行,而只能退而求其次進行開環評測。而開環評測指標的可靠度非常低,因為開環評測無法識別出模型混淆因果的問題,所以模型即使只學到了利用歷史路徑外插也能獲得非常好的開環指標,但這樣的模型是完全不可用的,2023年百度曾經發表一篇叫做AD-MLP的Paper(https://arxiv.org/pdf/2305.10430)來討論開環規劃評測指標的不足,這篇Paper僅僅是用了歷史信息,而沒有引入任何感知,就獲得了非常不錯的開環評測指標,甚至接近一些目前的SOTA工作,然而顯而易見,沒有人能在閉上眼睛的情況下開好車!
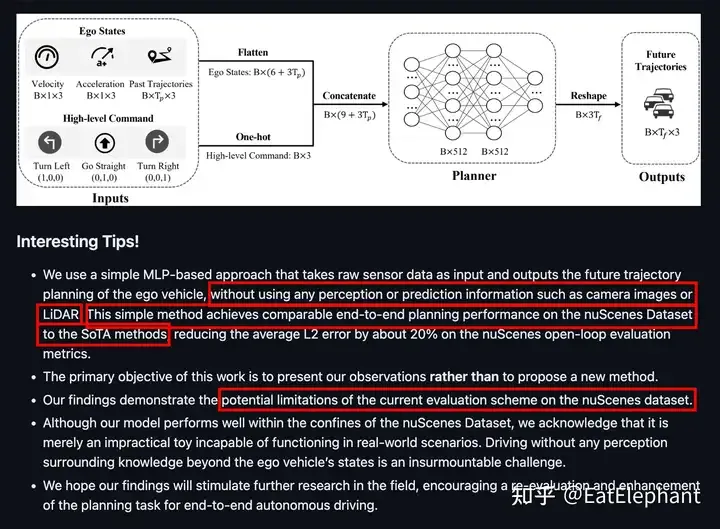
AD MLP通過不依賴感知輸入取得不錯的開環指標來說明用開環指標作為參考實際意義不大
那么閉環方針驗證是否能夠解決開環模仿學習的問題呢?至少目前來講學術界普遍依賴的CARLA閉環仿真系統來進行端到端的研發,但是基于游戲引擎的CARLA獲得的模型也很難遷移到現實世界來。
疑惑四:端到端自動駕駛僅僅是一次算法革新?
最后端到端不僅僅是一個新的算法那么簡單。模塊化的自動駕駛系統不同模塊的模型可以使用各自任務的數據分別迭代訓練,然而端到端系統各個功能是同時進行訓練的,這就要求訓練數據具有極高的一致性,每條數據要對所有子任務標簽都進行標注,一旦一種任務標注失敗,那這條數據就很難在端到端訓練任務中使用了,這對于自動標注Pipeline的成功率和性能提出了極高的要求。其次端到端系統因為需要所有模塊都達到一個較高的性能水平才能在端到端的決策規劃輸出任務中達成較好的效果,因此普遍認為端到端系統數據門檻遠高于各個單個模塊的數據需求,而數據的門檻不僅是對絕對數量的要求,還對于數據的分布和多樣性要求極高,這就是得自己沒有車輛的完全控制權,不得不適配多個擁有不同車型客戶的供應商在開發端到端系統時候可能遇到較大的困難。在算力門檻上,Musk曾在今年三月初在http://X.com上表示目前FSD的最大限制因素是算力,而在最近馬老板則表示他們的算力問題得到了很大的環節,幾乎就在同一時間在2024年Q1財報會議上Tesla透露如今他們已經擁有35000塊H100的計算資源,并透漏在2024年底這一數字將達到85000塊。毫無疑問Tesla擁有非常強大的算力工程優化能力,這意味著要達到FSD V12目前的水平,大概率35000塊H100和數十億美金的基礎設施資本開銷是必要前提,如果在算力使用方面不如Tesla高效,那么可能這一門檻會被進一步拔高。
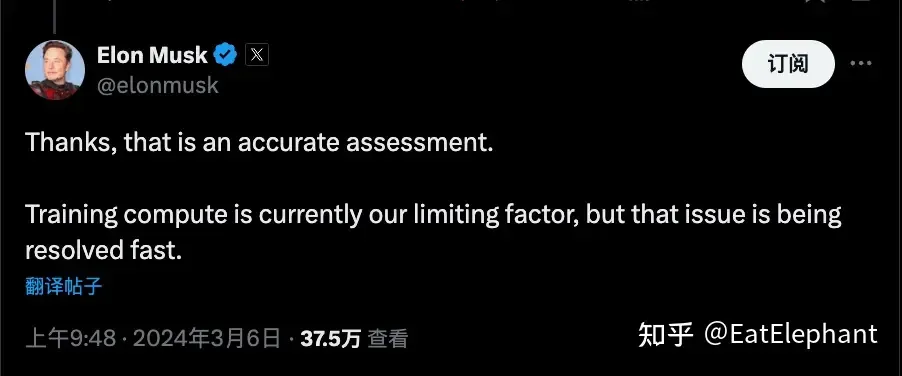
3月初馬斯克表示FSD的迭代主要限制因素是算力

4月初馬斯克表示今年Tesla在算力方面的總投入將超過100億美元
另外在http://X.com有網友分享了一張Nvidia汽車行業的高管Norm Marks在今年某次會議的截圖,從中可以看出截止到2023年底,Tesla所擁有的NV顯卡數量在柱狀圖上是完全爆表的存在(左圖最右側綠的箭頭,中間文字說明了這個排名第一的OEM所擁有的NV顯卡數量 > 7000個DGX節點,這個OEM顯然就是Tesla,每個節點按照8卡計算,23年底Tesla大概有A100顯卡超過56000卡,比排名第二的OEM多出四倍以上,這里我理解不包括2024年新購入的35000卡新款H100),再結合美國對出口中國顯卡的限制政策,想要趕超這一算力的難度變得更加困難。

Norm Marks在某次內部分享截圖,來源X.com@ChrisZheng001
除了上述數據算力挑戰外,端到端的系統會遇到什么樣的新挑戰,如何保證系統的可控性,如何盡早發現問題,通過數據驅動的方式解決問題,并且在無法利用規則代碼的情況下快速迭代,目前對于絕大多數自動駕駛研發團隊而言都是一個未知的挑戰。
最后端到端對于現在的自動駕駛研發團隊還是一個組織變革,因為從L4自動駕駛以來,絕大多數自動駕駛團隊的組織架構是模塊化的,不僅分為感知組,預測組,定位組,規劃控制組,甚至感知組還分視覺感知,激光感知等等。而端到端的技術架構直接干掉了不同模塊間的接口壁壘,使得研發端到端的團隊需要整合全部人力資源來適應新的技術范式,這對不夠靈活的團隊組織文化是一個極大的挑戰。




























