













一文看懂K8s集群的按需縮放、靈活降本
降本提效是創新開發的永恒話題。過去多年來,開發者紛紛擁抱容器技術以提高部署效率,降低運維負擔。隨著像Docker這類容器引擎使用量不斷增長,作為Docker管理系統的Kubernetes(簡稱K8s)順勢而出,幫助開發者構建并簡化復雜的容器編排工作。
延伸閱讀,點擊鏈接了解 Akamai Cloud Computing
本文Akamai將帶大家一起看看,如何準確確定Kubernetes集群的規模,并根據需求更靈活、動態地對集群規模進行縮放,從而在滿足負載需求的同時最大限度降低成本。
一、高效確定Kubernetes集群的最優規模
每當我們需要創建Kubernetes集群時,肯定首先都會問自己:該用什么類型的工作節點?具體需要多少個?
例如,當我們正在使用Linode Kubernetes引擎(LKE)等托管式Kubernetes服務,到底該使用8個2GB的Linode實例,還是2個8GB的Linode實例來實現所需計算能力?
在回答這個問題之前需要注意:無論自建K8s集群或任何云平臺上托管的K8s,并非所有工作節點中的資源都可以用于運行工作負載。
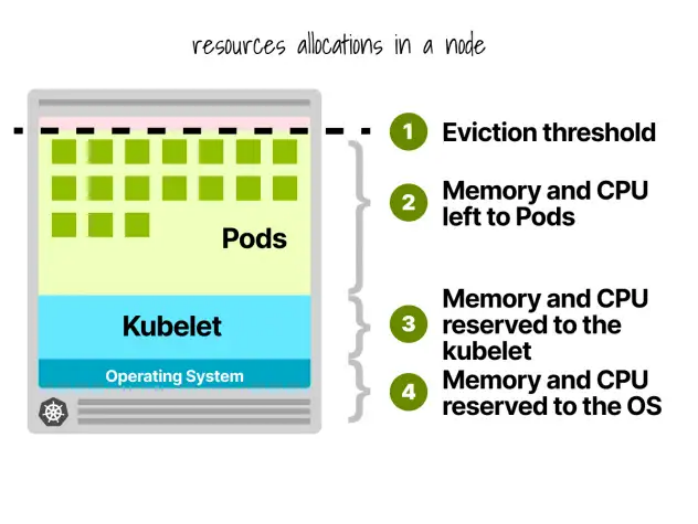
1.Kubernetes節點預留
在Kubernetes節點中,CPU和內存會被劃分給:
- 操作系統
- Kubelet、CNI、CRI、CSI(和系統守護程序)
- Pod
- 驅逐閾值
假設有個只有一個Linode 2GB計算實例的集群(包含1個vCPU和2GB內存),以下資源會被保留給kubelet和操作系統:
- 500MB內存。
- 60m的CPU。
此外,還有100MB內存為驅逐閾值保留。
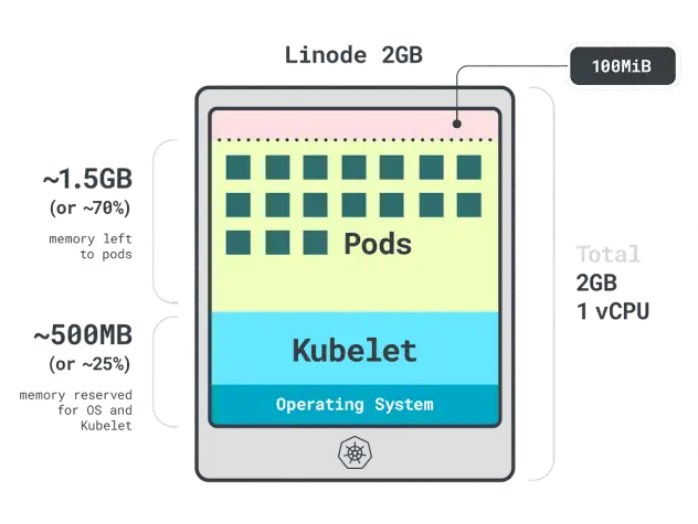
總的來說,此時我們有30%的內存和6%的CPU是不能被工作負載使用的。
每個云提供商都有各自定義限制的方式,但在CPU方面他們似乎不約而同進行了以下限制:
- 第一個核心的6%;
- 下一個核心的1%(最多2個核心);
- 接下來的2個核心的0.5%(最多4個);以及
- 四個以上核心的0.25%。
至于內存方面的限制,不同提供商之間有很大差異。但一般來說,內存的預留往往遵循以下限制:
- 前4GB內存的25%;
- 接下來4GB內存的20%(最多8GB);
- 接下來8GB內存的10%(最多16GB);
- 下一個112GB內存的6%(最多128GB);以及
- 超過128GB的任何內存的2%。
既然知道了工作節點內資源的分配方式,那么我們該選擇哪種實例?答案因具體情況而異,我們需要根據工作負載的實際情況來選擇最佳工作節點。
2.剖析應用程序
Kubernetes中有兩種方法來指定容器可以使用多少內存和CPU:
- 請求:通常與正常操作時的應用程序消耗量相匹配。
- 限制:設置允許的最大資源數量。
Kubernetes調度程序使用請求來確定在集群中分配Pod的位置。由于調度程序不知道消耗情況(Pod尚未啟動),因此它需要一個提示。這些“提示”就是請求;我們可以為內存和CPU分別設置請求。
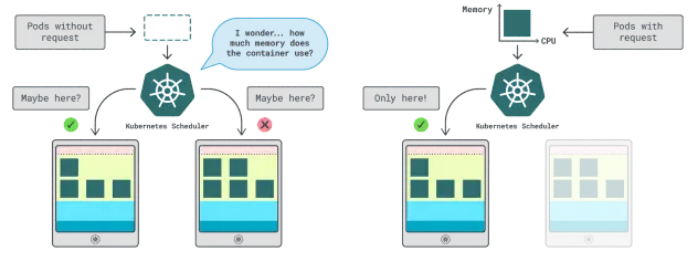
kubelet使用限制在內存使用超出允許范圍時停止進程。如果使用的CPU時間超過允許的范圍,kubelet也會限制該進程。但是,該如何選擇適當的請求和限制值呢?
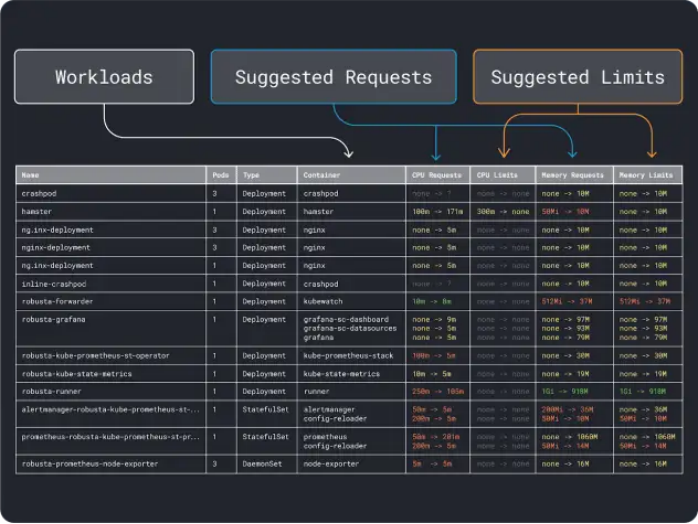
我們可以測量工作負載性能(例如平均值、95和99百分位數等)并將其用作請求和限制。為了簡化該過程,可以通過兩個便利的工具來加速分析:
- Vertical Pod Autoscaler
- Kubernetes Resource Recommender
VPA會收集內存和CPU利用率數據,并運行一個回歸算法,為我們的部署建議請求和限制。這是一個官方的Kubernetes項目,也可以用于自動調整值:我們可以讓控制器直接在YAML中更新請求和限制。
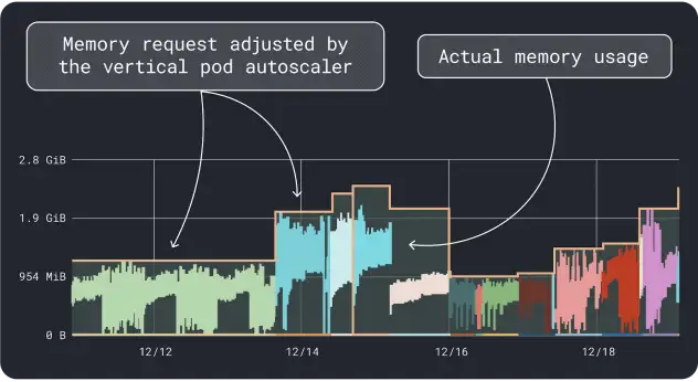
KRR的工作原理類似,但它利用了我們通過Prometheus導出的數據。作為第一步,工作負載應該被配置為將度量數據導出到Prometheus。一旦存儲了所有度量數據,就可以使用KRR來分析數據并建議請求和限制。
在具備了(粗略的)資源需求概念后,終于可以繼續選擇一個實例類型了。
3.選擇實例類型
假設估算自己的工作負載需要2GB的內存請求,并且估計至少需要約10個副本。我們可以排除大多數小于2GB的小型實例。此時也許可以直接使用某些大型實例,例如Linode 32GB。
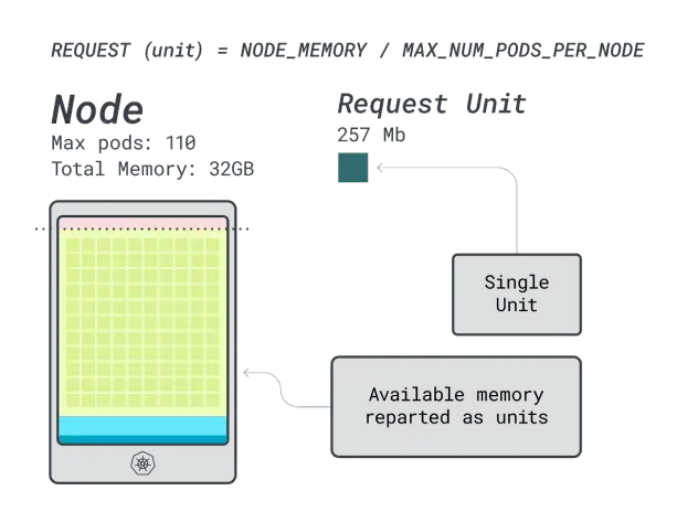
接下來,可以將內存和CPU除以可部署在該實例上的最大Pod數量(例如在LKE中的110個),以獲得內存和CPU的單元數量。
例如,Linode 32GB的CPU和內存單元為:
- 內存單元為257MB(即(32GB – 3.66GB預留)/ 110)
- CPU單元為71m(即(8000m – 90m預留)/ 110)
在最后一步中,我們可以使用這些單元來估算有多少工作負載可以適應節點。
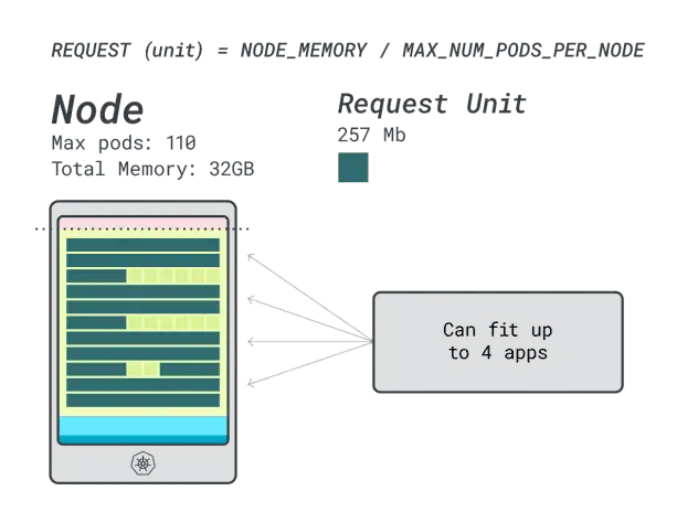
假設想要部署一個Spring Boot,請求為6GB和1 vCPU,這相當于:
- 適合6GB的最小單元是24個單元(24 * 257MB = 6.1GB)
- 適合1 vCPU的最小單元是15個單元(15 * 71m = 1065m)
這些數字表明,內存耗盡之前受限會將CPU耗盡,并且最多可以在集群中部署(110/24)4個應用程序。
當我們在此實例上運行四個工作負載時,將使用:
- 24個內存單元* 4 = 96個單元,有14個未使用(約12%)
- 15個vCPU單元 * 4 = 60個單元,有50個未使用(約45%)
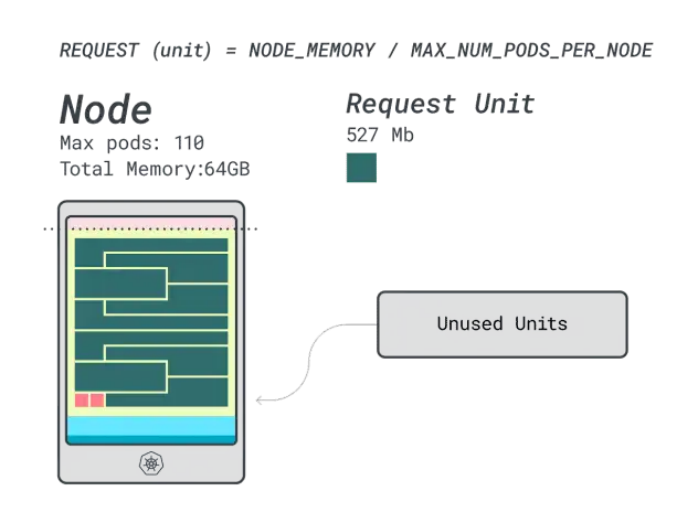
還不錯,但能做得更好嗎?讓我們嘗試使用Linode 64GB實例(64GB / 16 vCPU)。
假設要部署相同的應用程序,數字會發生一些變化:
- 內存單元約為527MB(即(64GB – 6.06GB預留)/ 110)。
- CPU單元約為145m(即(16000m – 110m預留)/ 110)。
- 適合6GB的最小單元是12個單元(12 * 527MB = 6.3GB)。
- 適合1 vCPU的最小單元是7個單元(7 * 145m = 1015m)。
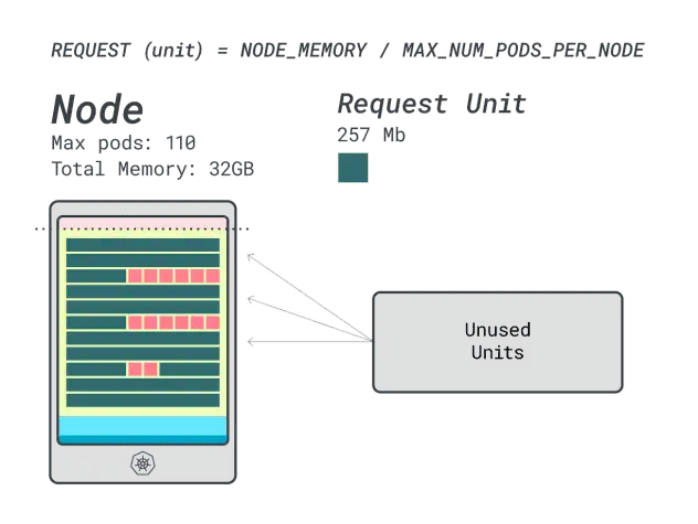
可以在這個實例中放多少工作負載?由于將耗盡內存,并且每個工作負載需要12個單元,所以最大應用程序數是9(即110/12)。

計算效率/浪費比例將會發現:
- 12個內存單元 * 9 = 108個單元,有2個未使用(約2%)
- 7個vCPU單元 * 9 = 63個單元,有47個未使用(約42%)
雖然浪費的CPU數量幾乎與前一個實例相同,但內存利用率得到了顯著改善。
最后,我們還可以比較一下成本:
- Linode 32GB實例最多可以容納4個工作負載。在這樣的總容量下,每個Pod的成本為每月48美元(即實例成本192美元除以4個工作負載)。
- Linode 64 GB實例最多可以容納9個工作負載。在這樣的總容量下,每個Pod的成本為每月42.6美元(即實例成本384美元除以9個工作負載)。

換句話說,選擇較大的實例可以為我們每月每個工作負載節省多達6美元。
4.使用計算器對比不同節點
如果想測試更多實例該怎么辦?進行這些計算需要很多工作。我們可以使用learnsk8s計算器加快該過程。
使用該計算器的第一步是輸入內存和CPU請求。系統會自動計算保留的資源并提供利用率和成本建議。此外還有一些額外的實用功能:按照應用程序用量分配最接近的CPU和內存請求。如果應用程序偶爾會突發高CPU或內存使用率,也可以靈活應對。
但是當所有Pod都將所有資源使用到極限會發生什么?這可能導致超額承諾。我們可以通過門戶中的小組件了解CPU和內存超額承諾的百分比。那么當超額承諾時具體又會發生什么?
- 如果內存超額承諾,kubelet將驅逐Pod并將其移動到集群中的其他位置。
- 如果CPU超額承諾,工作負載將按比例使用可用的CPU。
最后,我們還可以使用DaemonSets和Agent小組件,這是一個方便的機制,可以模擬在所有節點上運行的Pod。例如,LKE將Cilium和CSI插件部署為DaemonSets。這些Pod使用的資源對工作負載不可用,應從計算中減去。該小組件可以幫我們做到這一點!
二、按需開關更省錢
為了盡可能降低基礎設施成本,我們可以在不使用某些資源時將其關閉。然而此時的挑戰之處在于,必要時該如何將資源自動打開。接下來我們一起看看如何使用Linode Kubernetes Engine(LKE)部署一個Kubernetes集群,并使用Kubernetes Events-Driven Autoscaler(KEDA)將其收縮到“零”,然后恢復原狀。
1.為何要收縮到零
假設我們在Kubernetes上運行了一個常見的資源密集型應用,但我們只需要在工作時間里運行。此時可能會希望在大家都下班后將其關閉,并在上班時間自動重新打開。
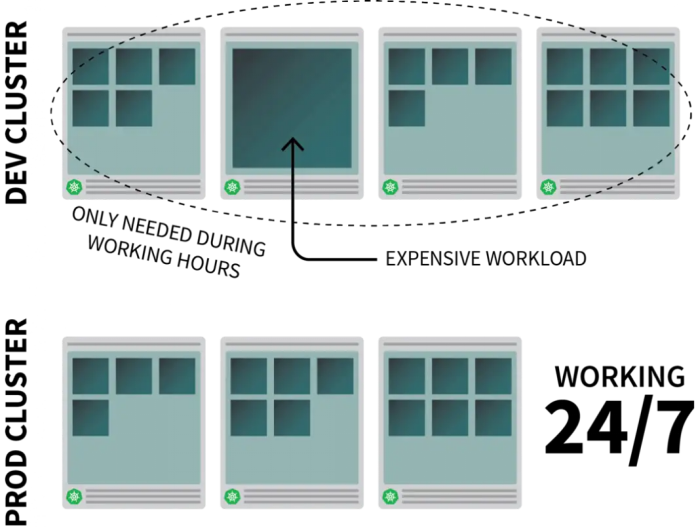
雖然可以使用CronJob來縮放實例,但這只是權宜之計,只能按照預先設定的時間表照計劃運行。
周末怎么辦?公共假期又如何處理?如果整個團隊都生病無法到崗呢?
與其編制一個不斷增長的規則列表,不如根據流量來擴展我們的工作負載。當流量增加時,可以擴展副本數量;當沒有流量時,可以將整個應用關閉。當應用關閉后又收到新的傳入請求后,Kubernetes會啟動至少一個副本來處理這些流量。

接下來一起看看該如何攔截去往應用程序的所有流量,監控流量,并設置Autoscaler調整副本數量或關閉應用。
2.創建集群
首先需要創建一個Kubernetes集群。可使用下列命令創建一個集群并保存kubeconfig文件。
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig通過下列命令驗證安裝過程已成功完成:
$ kubectl get pods -A --kubecnotallow=kubeconfig用環境變量導出kubeconfig文件通常是一種比較方便的做法。為此可以運行:
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods接著需要部署應用程序。
3.部署應用程序
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfo
使用下列命令提交YAML文件:
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yaml隨后即可訪問該應用,為此請打開瀏覽器并訪問localhost:8080。
$ kubectl port-forward svc/podinfo 8080:80接著應該就能看到這個應用了。
接下來需要安裝KEDA,也就是本例中將會用到的Autoscaler。
4.KEDA:Kubernetes事件驅動的Autoscaler
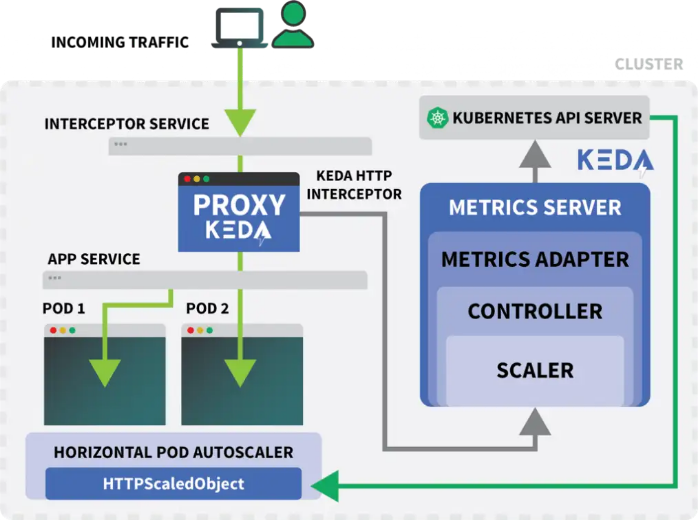
Kubernetes提供的Horizontal Pod Autoscaler(HPA)可以作為控制器動態增減副本數量。然而HPA有一些不足之處:
- 無法拆箱即用,需要安裝Metrics Server匯總和暴露指標。
- 無法縮放至零副本。
- 只能根據指標縮放副本,并且無法攔截HTTP流量。
好在并非只能使用官方提供的Autoscaler,我們還可以使用KEDA。KEDA是一種為下列三個組件打造的Autoscaler:
- Scaler
- Metrics Adapter
- Controller
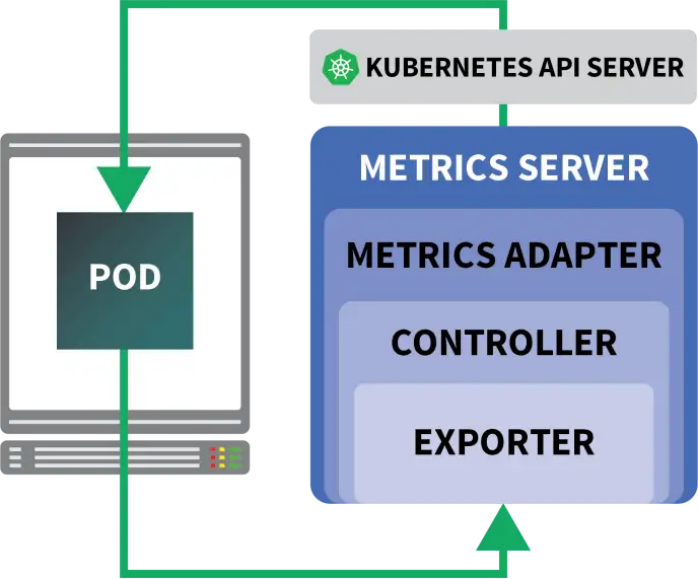
Scaler類似于適配器,可以從數據庫、消息代理、遙測系統等處收集指標。例如,HTTP Scaler這個適配器就可以攔截并收集HTTP流量。我們可以在這里看到一個 使用RabbitMQ的Scaler范例。
Metrics Adapter負責以Kubernetes指標管道可以使用的格式導出Scaler所收集的指標。
最后,Controller可以將所有這些組件緊密結合在一起:
- 使用適配器收集指標,并將其暴露給指標API。
- 注冊并管理KEDA指定的自定義資源定義(CRD),例如ScaledObject、TriggerAuthentication等。
- 代替我們創建并管理Horizontal Pod Autoscaler。
理論上的介紹就是這些了,一起看看它們實際上是如何起效的。
我們可以使用Helm快速安裝Controller,詳細的說明和介紹請參閱Helm官網。
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDA默認并不包含HTTP Scaler,因此需要單獨安裝:
$ helm install http-add-on kedacore/keda-add-ons-http隨后就可以擴展我們的應用了。
5.定義Autoscaling策略
KEDA的HTTP加載項會暴露出一個CRD,借此我們可以描述應用程序的擴展方式。一起看一個例子:
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10該文件會指示攔截器將有關http://example.com的請求轉發給podinfo服務。
其中還包含了需要擴展的部署的名稱,本例中為podinfo。
使用下列命令將YAML提交至集群:
$ kubectl apply -f scaled-object.yaml提交了上述定義后,Pod被刪除了!為何會這樣?
在創建了HTTPScaledObject后,KEDA會立即將該部署收縮到零,因為目前沒有流量。
為了進行擴展,我們必須向應用發出HTTP請求。試試看連接到該服務并發出一個請求。
$ kubectl port-forward svc/podinfo 8080:80這個命令被掛起了!
這種現象是合理的,因為目前沒有可以為請求提供服務的Pod。但Kubernetes為何沒有將該部署擴展為1?
6.測試KEDA攔截器
在使用Helm安裝加載項時,會創建一個名為keda-add-ons-http-interceptor-proxy的Kubernetes服務。為了讓自動擴展能夠正常起效,HTTP流量必須首先通過該服務進行路由。我們可以用kubectl port-forward進行測試:
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080這一次我們無法在瀏覽器中訪問該URL。
一個KEDA HTTP攔截器可以處理多個部署,那么它如何知道要將流量路由到哪里?
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10針對這種情況,HTTPScaledObject使用了一個host 段。在本例中,我們需要假裝請求來自http://example.com。為此需要設置Host頭:
$ curl localhost:8080 -H 'Host: example.com'我們將收到一個回應,盡管略微有些延遲。
檢查Pod會發現,部署已經被擴展至一個副本:
$ kubectl get pods那么剛才到底發生了什么?
在將流量路由至KEDA的服務時,攔截器會追蹤尚未收到回復的未決HTTP請求數量。KEDA Scaler會定期檢查攔截器的隊列大小,并存儲相關指標信息。
KEDA Controller會監控指標,并根據需要增大或減小副本數量。本例中有一個未決請求,此時KEDA Controller將部署擴展為一個副本就已足夠。
我們可以通過下列方式獲取每個攔截器的未決HTTP請求隊列狀態:
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}由于這種設計的存在,我們必須慎重決定該用何種方式將流量路由給應用。KEDA只能在流量可被攔截的情況下才會對部署進行擴展。
如果有一個現有的入口Controller,并且希望使用該Controller將流量轉發給應用,那么還需要修改入口清單,將流量轉發給HTTP加載項服務。一起看一個例子。
7.將KEDA HTTP加載項與入口配合使用
我們可以使用Helm安裝Nginx-ingress controller:
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace隨后寫一個入口清單,將流量路由給podinfo:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080通過下列命令可以獲取負載均衡器的IP地址:
LB_IP=$(kubectl get services -l "app.kubernetes.io/compnotallow=controller" -o jsnotallow="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)最后使用下列命令向應用發出一個請求:
curl $LB_IP -H "Host: example.com"起作用了!如果等待足夠長的時間,我們還將注意到,該部署最終被收縮到零。
三、通過Autoscaler實現Kubernetes的伸縮
在設計Kubernetes集群時,我們可能經常需要回答以下問題:
- 集群伸縮需要多長時間?
- 在新Pod創建之前需要等待多長時間?
有四個主要因素會影響集群的伸縮:
- Horizontal Pod Autoscaler的反應時間;
- Cluster Autoscaler的反應時間;
- 節點預配時間;以及
- Pod創建時間。
下文將依次討論這些因素。
默認情況下,kubelet每10秒從Pod中提取一次CPU使用情況數據,而Metrics Server每1分鐘從kubelet獲取一次這些數據。Horizontal Pod Autoscaler每30秒檢查一次CPU和內存度量。
如果度量超過閾值,Autoscaler會增加Pod的副本數,并在采取進一步行動之前暫停3分鐘。在最糟糕的情況下,可能要等待長達3分鐘才能添加或刪除Pod,但平均而言,用戶應該期望等待1分鐘后Horizontal Pod Autoscaler即可觸發伸縮。
 Horizontal Pod Autoscaler的反應時間
Horizontal Pod Autoscaler的反應時間
Cluster Autoscaler會檢查是否有待處理的Pod,并增加集群的大小。檢測到需要擴展集群可能需要:
- 在具有少于100個節點和3000個Pod的集群上最多需要30秒,平均延遲約為5秒;或
- 在具有100個以上節點的集群上最多需要60秒的延遲,平均延遲約為15秒。
 Cluster Autoscaler的反應時間
Cluster Autoscaler的反應時間
Linode上的節點預配,也就是從Cluster Autoscaler觸發API到新創建節點上可以調度Pod,這一過程需要大約3-4分鐘時間。
 Linode的預配時間
Linode的預配時間
簡而言之,對于小規模集群,我們會面臨:
- HPA延遲:1m +
- CA延遲:0m30s +
- 云提供商:4m +
- 容器運行時:0m30s +
——————————————
總計6m
 端到端Autoscaler反應時間
端到端Autoscaler反應時間
對于具有100個以上節點的集群,總延遲可能為6分30秒…… 這是一個相當長的時間,那么該如何解決這個問題?可以主動調整工作負載,或者如果非常了解流量模式,也可以提前伸縮。
1.使用KEDA進行預伸縮
如果流量的變化模式可預測,那么在高峰之前擴展工作負載(和節點)就是可行的。
Kubernetes沒有提供根據日期或時間擴展工作負載的機制,但我們可以使用上文提到的KEDA實現目標。
使用Helm安裝KEDA:
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda安裝好Prometheus和KEDA后,創建一個部署。
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo用下列命令將資源提交到集群:
$ kubectl apply -f deployment.yamlKEDA在現有的Horizontal Pod Autoscaler之上工作,并使用名為ScaleObject的自定義資源定義(CRD)進行包裝。下列ScaledObject使用Cron Scaler定義了更改副本數的時間窗口:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"用下列命令提交對象:
$ kubectl apply -f scaled-object.yaml接下來會發生什么?什么也不會發生。自動伸縮只會在23 * * * *到28 * * * *之間觸發。在Cron Guru的幫助下,我們可以將這兩個Cron表達式翻譯成:
- 從第23分鐘開始(例如2:23、3:23等)。
- 在第28分鐘停止(例如2:28、3:28等)。
如果等到開始時間,我們將注意到副本數增加到5。
 使用KEDA通過Cron表達式進行伸縮
使用KEDA通過Cron表達式進行伸縮
在第28分鐘后,副本數是否恢復到1?是的,自動伸縮器會恢復為minReplicaCount中指定的副本數。
如果在其中一個時間間隔內增加副本數會發生什么?如果在23和28分鐘之間,我們將部署的副本數擴展到10,KEDA將覆蓋我們的更改并設置計數。如果在第28分鐘后重復相同實驗,副本數將設置為10。
在了解了理論后,讓我們看一些實際用例。
2.在工作時間內伸縮
假設我們在開發環境中部署了一個應該在工作時間段內處于活躍狀態,并且在夜間應該關閉的工作負載。
可以使用以下ScaledObject:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"默認副本數為零,但在工作時間(上午9點到下午5點)期間,副本會擴展到10個。
 僅在工作時間內擴展工作負載
僅在工作時間內擴展工作負載
我們還可以擴展Scaled Object以排除周末:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"這樣,工作負載將僅在周一至周五的9點到17點活躍。由于可以組合多個觸發器,因此還可以包括一些例外情況。
3.在周末伸縮
我們可能計劃在星期三讓工作負載保持更長時間,為此可使用以下定義:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"在此定義中,工作負載會在周一至周五的9點到17點之間處于活動狀態,但星期三會從9點持續到21點。
總結
按需縮放是一種有效降低成本的方法。Kubernetes作為一種容器編排平臺,提供了自動化管理和部署容器化應用程序的功能,使得按需縮放變得更加容易實現。
根據本文提供的思路,我們可以根據應用程序的需求變化情況,動態調整資源,并在需要時自動擴展或縮減規模,從而降低成本并提高資源利用率。
本文所涉及的內容,不僅適用于Linode平臺上提供的托管式Kubernetes集群,也同樣適用于大家在本地環境或其他云平臺上部署的集群。希望這些內容對大家有所幫助,也歡迎關注Akamai機構號,了解更多通過云平臺降本增效的技巧。
—————————————————————————————————————————————————
如您所在的企業也在考慮采購云服務或進行云遷移,
點擊鏈接了解Akamai Linode的解決方案























