













大模型擴展新維度:Scaling Down、Scaling Out
本文由悉尼大學計算機學院王云柯,李言蹊和徐暢副教授完成。王云柯是悉尼大學博士后,李言蹊是悉尼大學三年級博士生,徐暢副教授是澳洲ARC Future Fellow,其團隊長期從事機器學習算法、生成模型等方向的研究。
近年來, Scaling Up 指導下的 AI 基礎模型取得了多項突破。從早期的 AlexNet、BERT 到如今的 GPT-4,模型規模從數百萬參數擴展到數千億參數,顯著提升了 AI 的語言理解和生成等能力。然而,隨著模型規模的不斷擴大,AI 基礎模型的發展也面臨瓶頸:高質量數據的獲取和處理成本越來越高,單純依靠 Scaling Up 已難以持續推動 AI 基礎模型的進步。
為了應對這些挑戰,來自悉尼大學的研究團隊提出了一種新的 AI Scaling 思路,不僅包括 Scaling Up(模型擴容),還引入了 Scaling Down(模型精簡)和 Scaling Out(模型外擴)。Scaling Down 通過優化模型結構,使其更輕量、高效,適用于資源有限的環境,而 Scaling Out 則致力于構建去中心化的 AI 生態系統,讓 AI 能力更廣泛地應用于實際場景。

- 論文標題:AI Scaling: From Up to Down and Out
- 論文鏈接:https://www.arxiv.org/abs/2502.01677
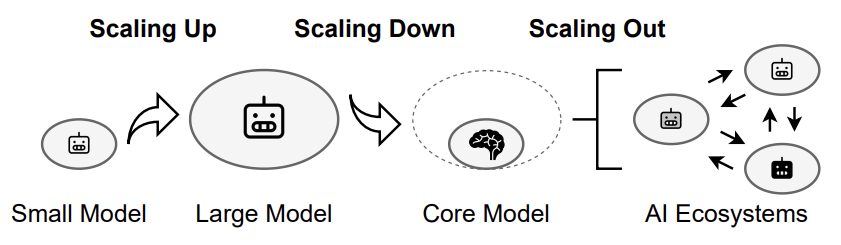
該框架為未來 AI 技術的普及和應用提供了新的方向。接下來,本文將詳細探討這一框架如何推動 AI Scaling 從集中化走向分布式,從高資源消耗走向高效普及,以及從單一模型衍生 AI 生態系統。
Scaling Up: 模型擴容,持續擴展基礎模型
Scaling Up 通過增加數據規模、模型參數和計算資源,使 AI 系統的能力得到了顯著提升。然而,隨著規模的不斷擴大,Scaling Up 也面臨多重瓶頸。數據方面,高質量公開數據已被大量消耗,剩余數據多為低質量或 AI 生成內容,可能導致模型性能下降。模型方面,參數增加帶來的性能提升逐漸減弱,大規模模型存在冗余、過擬合等問題,且難以解釋和控制。計算資源方面,訓練和推理所需的硬件、能源和成本呈指數級增長,環境和經濟壓力使得進一步擴展變得不可持續。
盡管面臨挑戰,規模化擴展仍是推動 AI 性能邊界的關鍵。未來的趨勢將聚焦于高效、適應性和可持續性的平衡:
數據優化:通過課程學習、主動學習等技術,利用更小規模的高質量數據集實現高效訓練。同時,處理噪聲數據和利用領域專有數據將成為突破點。
高效訓練:采用漸進式訓練、分布式優化和混合精度訓練等方法,減少資源消耗,提升訓練效率,推動 AI 開發的可持續性。
Test-Time Scaling:通過在推理階段動態分配計算資源,提升模型性能。例如,自適應輸出分布和驗證器搜索機制使小型模型在某些任務上超越大型模型,為高效 AI 提供了新方向。
AI Scaling Up 的未來不僅在于「更大」,更在于「更智能」和「更可持續」。通過優化數據、訓練和推理流程,AI 有望在突破性能邊界的同時,實現更廣泛的應用和更低的環境成本。
Scaling Down: 模型精簡,聚焦核心模塊
隨著 Scaling Up 所需的訓練、部署和維護計算資源、內存和能源成本急劇增加,一個關鍵問題浮出水面:如何在縮小模型規模的同時,保持甚至提升其性能?Scaling Down 旨在減少模型規模、優化計算效率,同時保持核心能力,使 AI 適用于更廣泛的資源受限場景,如邊緣設備和移動端應用。
技術基礎
1. 減少模型規模:剪枝,通過移除神經網絡中不重要的部分來簡化模型;量化,將浮點參數替換為整數,減少權重和激活的比特寬度;知識蒸餾,將大型復雜模型的知識遷移到小型高效模型中。
2. 優化計算效率:投機采樣,通過近似模型生成候選詞,再由目標模型并行驗證,加速推理過程;KV Caching,存儲注意力機制的中間狀態,避免重復計算;混合專家模型,通過任務特定的子模型和門控機制實現高效擴展。例如,DeepSeek-V3 通過專家模型的選擇性激活,顯著降低推理過程中的計算成本。
未來這一領域的研究可能聚焦以下方向。首先,核心功能模塊的提煉將成為重點。未來的研究將致力于識別大型模型中的關鍵功能模塊,力求在保留核心功能的前提下,最大限度地減少冗余結構。通過系統化的剪枝和知識蒸餾技術,開發出更精細的模型架構優化方法,從而在縮小規模的同時不損失性能。
其次,外部輔助增強將為小模型提供新的能力擴展途徑。例如,檢索增強生成(RAG)技術通過結合預訓練的參數化記憶和非參數化記憶,使模型能夠動態獲取上下文相關信息;而工具調用技術則讓小模型學會自主調用外部 API,甚至生成自己的工具以應對復雜任務。
Scaling Out: 模型外擴,構建 AI 生態系統
在 Scaling Up 和 Scaling Down 之后,文章提出 Scaling Out 作為 AI Scaling 的最后一步,其通過將孤立的基礎模型擴展為具備結構化接口的專業化變體,將其轉化為多樣化、互聯的 AI 生態系統。在該生態系統中,接口負責連接專業化模型與用戶、應用程序和其他 AI 系統。這些接口可以是簡單的 API,也可以是能夠進行多輪推理和決策的 Agent。
通過結合基礎模型、專用變體和接口,Scaling Out 構建了一個動態的 AI 生態系統,包含多個 AI 實體在其中交互、專業化并共同提升智能。這一生態促進了協作,能夠實現大規模部署,并不斷拓展 AI 的能力,標志著 AI 向開放、可擴展、去中心化的智能基礎架構轉變。
技術基礎
1. 參數高效微調:傳統的微調需要大量計算資源,但參數高效微調技術如 LoRA 允許在不修改整個模型的情況下添加任務特定知識。
2. 條件控制:使基礎模型能夠動態適應多種任務,而無需為每個任務重新訓練。例如,ControlNet 通過結構引導生成上下文感知圖像。
3. 聯邦學習:支持在分布式設備上協作訓練 AI 模型,確保數據隱私和安全。聯邦學習允許在多樣化、領域特定的數據集上訓練專業化子模型,增強其適應能力。
未來這一領域的研究可能聚焦于以下方向。首先,去中心化 AI 和區塊鏈 。AI 模型商店將像應用商店一樣提供多樣化模型,區塊鏈則作為信任層,確保安全性、透明性和知識產權保護。每一次微調、API 調用或衍生模型創建都將被記錄在不可篡改的賬本上,確保信用歸屬和防止未經授權的修改。其次,邊緣計算與分布式智能。邊緣計算在本地設備上處理數據,減少對集中式數據中心的依賴。結合聯邦學習,邊緣計算能夠在保護隱私的同時,實現實時決策和分布式智能。
應用場景設想
人機共創社區如 TikTok 等,將迎來智能內容創作的新紀元。內容創作者不再僅限于人類,AI 驅動的 Bots 將成為重要組成部分。這些 Bots 能夠自主生成高質量短視頻,與其他用戶互動,甚至彼此協作,推動內容創作的多樣性與復雜性。
Scaling Up 是整個體系的基石,通過整合 TikTok 全球用戶的多模態數據,開發出強大的多模態基礎模型,為 Bots 提供內容生成、互動和創意的核心能力。然而,僅靠一個巨型模型難以滿足多樣化需求,Scaling Down 將基礎模型的核心能力提煉為輕量化模塊,使 AI Bots 能夠高效、靈活地執行任務,降低計算成本并適應多樣化場景部署。
最終,Scaling Out 將 TikTok 推向智能生態的全新高度。通過任務驅動的生成機制,平臺能夠快速擴展出數以萬計的專用 Bots,每個 Bot 都針對特定領域(如教育、娛樂、公益)進行了深度優化。這些 Bots 不僅可以單獨運行,還能通過協作網絡共享知識,構建實時進化的內容網絡,為用戶提供無窮無盡的創意和互動體驗。
挑戰與機遇
此外,文中探討了 AI Scaling 在跨學科合作、量化標準、開放生態、可持續性和公平性方面的機遇與難點。
AI Scaling 需要跨學科合作,結合認知科學、神經科學、硬件工程和數據科學,提升計算效率和適應性。同時,需要建立量化標準,例如評估模型大小、計算成本與性能的關系,為 AI 發展提供清晰的參考。
開放生態是 AI Scaling 發展的關鍵,輕量級核心模型和開放 API 可以促進 AI 在醫療、農業、工業等行業的落地應用。為了實現可持續發展,Scaling Down 通過輕量化 AI 減少能耗,Scaling Out 則通過分布式和多接口擴展,降低對數據中心的依賴,從而提升全球可及性。
最終,AI Scaling 將為通用人工智能(AGI)奠定基礎。Scaling Up 提供基礎知識,Scaling Down 提高適應性,Scaling Out 構建開放、去中心化的 AI 生態系統,該系統中的不同接口相互協同,共同應對復雜挑戰。




























