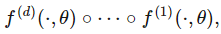神經(jīng)網(wǎng)絡(luò)的泛化能力:數(shù)學(xué)分析與提升策略
從圖像識別到語音處理,從自然語言理解到復(fù)雜系統(tǒng)的預(yù)測,神經(jīng)網(wǎng)絡(luò)的應(yīng)用無處不在。
然而,一個關(guān)鍵問題始終困擾著研究人員和實踐者:神經(jīng)網(wǎng)絡(luò)的泛化能力。
泛化能力決定了神經(jīng)網(wǎng)絡(luò)在面對新的、未見過的數(shù)據(jù)時,能否準(zhǔn)確地進行預(yù)測和決策。
本文將深入探討神經(jīng)網(wǎng)絡(luò)的泛化能力,從數(shù)學(xué)的角度進行分析,并提出有效的提升策略,幫助讀者更好地理解和應(yīng)用神經(jīng)網(wǎng)絡(luò)。
PART1.泛化能力的數(shù)學(xué)定義
首先,我們用一個簡單的例子來解釋泛化能力。假設(shè)你正在訓(xùn)練一個神經(jīng)網(wǎng)絡(luò)模型來識別貓和狗的圖片。在訓(xùn)練過程中,模型看到了大量的貓和狗的圖片,并學(xué)會了區(qū)分它們。
 圖片
圖片
但是,當(dāng)模型遇到一張它從未見過的貓的圖片時,它能否正確地識別出這是一只貓呢?這就是泛化能力所關(guān)注的問題。
泛化能力是指神經(jīng)網(wǎng)絡(luò)在新的、未見過的數(shù)據(jù)上表現(xiàn)的能力。
在數(shù)學(xué)上,泛化能力可以通過泛化誤差來定義。泛化誤差是指神經(jīng)網(wǎng)絡(luò)在真實數(shù)據(jù)分布上的誤差,即網(wǎng)絡(luò)在所有可能的數(shù)據(jù)上的平均誤差。用公式表示為:

以下是衡量模型泛化能力的常見指標(biāo):
1. 測試誤差:測試誤差是衡量泛化能力最直接的方法。它是在獨立的測試數(shù)據(jù)集上計算的誤差。
 圖片
圖片
測試數(shù)據(jù)集是網(wǎng)絡(luò)在訓(xùn)練過程中從未見過的數(shù)據(jù),因此測試誤差能夠很好地反映網(wǎng)絡(luò)在新數(shù)據(jù)上的表現(xiàn)。
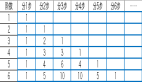
2. 交叉驗證誤差:交叉驗證是一種更穩(wěn)健的評估方法。它將數(shù)據(jù)集分成多個子集,每次用其中一個子集作為測試集,其余子集作為訓(xùn)練集。
 圖片
圖片
通過多次訓(xùn)練和測試,計算平均誤差來評估網(wǎng)絡(luò)的泛化能力。這種方法可以減少測試誤差的偶然性,更準(zhǔn)確地反映網(wǎng)絡(luò)的泛化性能。
3. 泛化誤差的估計:在實際應(yīng)用中,我們通常無法直接計算泛化誤差,因為它涉及到對真實數(shù)據(jù)分布的期望。
 圖片
圖片
但是,我們可以通過一些統(tǒng)計方法來估計泛化誤差。例如,使用 Hoeffding 不等式可以給出泛化誤差的一個概率上界,幫助我們了解網(wǎng)絡(luò)泛化能力的可靠性。
PART2.影響泛化能力的因素分析
模型的泛化能力是衡量其在未見過的新數(shù)據(jù)上表現(xiàn)能力的關(guān)鍵指標(biāo),而模型復(fù)雜度、數(shù)據(jù)質(zhì)量與數(shù)量、訓(xùn)練算法與優(yōu)化策略是影響泛化能力的三個主要因素。以下是對這些因素的詳細分析:
1.設(shè)計思想
模型復(fù)雜度是影響泛化能力的關(guān)鍵因素之一。一個復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型,如深度很大的網(wǎng)絡(luò)或參數(shù)數(shù)量很多的網(wǎng)絡(luò),具有很強的擬合能力。
它可以完美地擬合訓(xùn)練數(shù)據(jù),甚至包括數(shù)據(jù)中的噪聲。然而,這種過度擬合會導(dǎo)致網(wǎng)絡(luò)在新的數(shù)據(jù)上表現(xiàn)不佳。
 圖片
圖片
例如,一個過擬合的網(wǎng)絡(luò)可能會將訓(xùn)練數(shù)據(jù)中的某些特定特征誤認為是分類的依據(jù),而在測試數(shù)據(jù)中這些特征可能并不存在,從而導(dǎo)致錯誤的預(yù)測。
另一方面,如果模型過于簡單,也可能導(dǎo)致泛化能力不足。
這種情況下,網(wǎng)絡(luò)無法捕捉到數(shù)據(jù)中的復(fù)雜模式,從而在訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)上都表現(xiàn)不佳。
 圖片
圖片
例如,一個只有幾層的簡單神經(jīng)網(wǎng)絡(luò)可能無法有效地學(xué)習(xí)到圖像中復(fù)雜的紋理和形狀特征,導(dǎo)致分類錯誤率較高。
2.數(shù)據(jù)質(zhì)量與數(shù)量
高質(zhì)量的數(shù)據(jù)對于神經(jīng)網(wǎng)絡(luò)的泛化能力至關(guān)重要。數(shù)據(jù)質(zhì)量包括數(shù)據(jù)的準(zhǔn)確性、完整性和代表性。
如果數(shù)據(jù)中存在錯誤或缺失值,或者數(shù)據(jù)不能很好地代表真實世界的情況,那么網(wǎng)絡(luò)的泛化能力將受到嚴重影響。
 圖片
圖片
例如,在一個醫(yī)療診斷任務(wù)中,如果訓(xùn)練數(shù)據(jù)中的病例不完整或存在錯誤診斷,那么網(wǎng)絡(luò)可能會學(xué)習(xí)到錯誤的模式,導(dǎo)致在實際應(yīng)用中誤診。
數(shù)據(jù)數(shù)量也是影響泛化能力的重要因素。一般來說,數(shù)據(jù)量越大,網(wǎng)絡(luò)的泛化能力越強。
更多的數(shù)據(jù)可以提供更豐富的信息,幫助網(wǎng)絡(luò)更好地學(xué)習(xí)數(shù)據(jù)中的模式和規(guī)律。
例如,在一個語言模型中,大量的文本數(shù)據(jù)可以幫助網(wǎng)絡(luò)學(xué)習(xí)到語言的復(fù)雜結(jié)構(gòu)和語義關(guān)系,從而在生成文本或翻譯文本時表現(xiàn)得更好。
3.訓(xùn)練算法與優(yōu)化策略
不同的訓(xùn)練算法對神經(jīng)網(wǎng)絡(luò)的泛化能力有不同的影響。
 圖片
圖片
例如,隨機梯度下降(SGD)算法在訓(xùn)練過程中引入了隨機性,這有助于網(wǎng)絡(luò)跳出局部最優(yōu)解,找到更全局的最優(yōu)解,從而提高泛化能力。
而一些更復(fù)雜的優(yōu)化算法,如 Adam 或 RMSprop,雖然在訓(xùn)練速度上可能更快,但在某些情況下可能會導(dǎo)致網(wǎng)絡(luò)過擬合。
正則化技術(shù)是提高泛化能力的重要手段。常見的正則化方法包括 L1 和 L2 正則化。
L1 正則化通過在損失函數(shù)中加入?yún)?shù)的絕對值來懲罰模型的復(fù)雜度,促使網(wǎng)絡(luò)學(xué)習(xí)到更稀疏的參數(shù)。
 圖片
圖片
L2 正則化則通過加入?yún)?shù)的平方來懲罰模型的復(fù)雜度,使網(wǎng)絡(luò)的參數(shù)更平滑。
這些正則化技術(shù)可以有效地防止網(wǎng)絡(luò)過擬合,提高泛化能力。
PART3.提升泛化能力的數(shù)學(xué)策略
為了提升模型的泛化能力,可以采用以下數(shù)學(xué)策略:數(shù)據(jù)增強、正則化、早停法。
這些策略從不同的角度出發(fā),通過增加數(shù)據(jù)的多樣性、限制模型的復(fù)雜度以及合理控制訓(xùn)練過程,有效地提高了模型在未見過的新數(shù)據(jù)上的表現(xiàn)。
1.正則化
如上所述,L1 和 L2 正則化是兩種常用的模型正則化方法。
通過對模型參數(shù)的范數(shù)進行約束,有效地防止模型過度擬合訓(xùn)練數(shù)據(jù),使模型在新數(shù)據(jù)上具有更好的泛化能力。
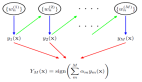
Dropout 則是另一種特殊的正則化技術(shù)。
在訓(xùn)練過程中,Dropout 隨機地丟棄網(wǎng)絡(luò)中的一些神經(jīng)元,使網(wǎng)絡(luò)在每次訓(xùn)練時都使用不同的子網(wǎng)絡(luò)。
 圖片
圖片
這種方法可以防止神經(jīng)元之間的共適應(yīng),提高網(wǎng)絡(luò)的泛化能力。
例如,在一個深度神經(jīng)網(wǎng)絡(luò)中,使用 Dropout 可以使網(wǎng)絡(luò)在訓(xùn)練過程中學(xué)習(xí)到更魯棒的特征,從而在測試數(shù)據(jù)上表現(xiàn)更好。
2.早停法
早停法是一種在訓(xùn)練過程中提前停止訓(xùn)練的方法,以防止網(wǎng)絡(luò)過擬合。其基本原理是通過監(jiān)控網(wǎng)絡(luò)在驗證集上的誤差,在誤差開始上升時停止訓(xùn)練。
從數(shù)學(xué)角度來看,早停法可以通過監(jiān)控驗證誤差的變化來實現(xiàn)。
假設(shè)驗證誤差為 驗證,訓(xùn)練誤差為 訓(xùn)練,那么早停法的目標(biāo)是找到一個合適的停止點 ,使得 驗證 最小化。具體來說,早停法可以通過以下步驟實現(xiàn):
- 初始化網(wǎng)絡(luò)參數(shù) 。
- 在每個訓(xùn)練步驟 上,計算訓(xùn)練誤差 訓(xùn)練 和驗證誤差 驗證。
- 如果 驗證 在連續(xù) 個步驟上沒有下降,則停止訓(xùn)練,返回當(dāng)前的網(wǎng)絡(luò)參數(shù) 。
 圖片
圖片
如上圖,當(dāng)網(wǎng)絡(luò)開始過擬合時,驗證誤差會逐漸增加,而訓(xùn)練誤差會繼續(xù)下降。
所以,通過早停法在網(wǎng)絡(luò)過擬合之前停止訓(xùn)練,可以有效地防止網(wǎng)絡(luò)過擬合,提高泛化能力。同時,也可以節(jié)省訓(xùn)練時間,提高訓(xùn)練效率。
3.數(shù)據(jù)增強
數(shù)據(jù)增強是一種通過生成新的訓(xùn)練數(shù)據(jù)來提高泛化能力的方法。它的基本原理是通過對原始數(shù)據(jù)進行變換,如旋轉(zhuǎn)、縮放、裁剪、顏色調(diào)整等,生成新的數(shù)據(jù)樣本。
從數(shù)學(xué)角度來看,數(shù)據(jù)增強可以通過數(shù)據(jù)分布的擴展來描述。
假設(shè)原始數(shù)據(jù)的分布為 原始,通過數(shù)據(jù)增強生成的新數(shù)據(jù)的分布為 增強,那么數(shù)據(jù)增強的目標(biāo)是使 增強 更接近真實數(shù)據(jù)分布 真實。
這些新的數(shù)據(jù)樣本在一定程度上模擬了真實世界中的數(shù)據(jù)變化,從而幫助網(wǎng)絡(luò)學(xué)習(xí)到更魯棒的特征。
 圖片
圖片
例如,在圖像識別任務(wù)中,通過對圖像進行旋轉(zhuǎn)和縮放,網(wǎng)絡(luò)可以學(xué)習(xí)到物體在不同角度和大小下的特征,從而在面對新的圖像時能夠更準(zhǔn)確地識別。
結(jié) 語
在本文中,我們深入探討了神經(jīng)網(wǎng)絡(luò)的泛化能力,從數(shù)學(xué)的角度進行了分析,并提出了多種提升策略。
我們首先定義了泛化能力,并介紹了衡量泛化能力的指標(biāo),如測試誤差和交叉驗證誤差。
然后,我們分析了影響泛化能力的因素,包括模型復(fù)雜度、數(shù)據(jù)質(zhì)量與數(shù)量以及訓(xùn)練算法與優(yōu)化策略。
接著,我們提出了多種提升泛化能力的策略,如數(shù)據(jù)增強、模型正則化和早停法。