卡帕西8000行代碼手搓ChatGPT,成本僅100美元,訓練12小時CORE表現(xiàn)超越GPT-2,手把手教程來了
100美元成本、8000行代碼純手搓克隆ChatGPT!
特斯拉前AI總監(jiān)、OpenAI創(chuàng)始成員、宣布全職搞教育的AI大神Andrej Karpathy(卡帕西)沉寂了好久,終于終于終于來上新課了!
新作nanochat,被其本人稱作是寫得最“精神錯亂”放飛自我的作品之一。
它是一個極簡的、從零開始構建的全棧訓練/推理pipeline,用最少量依賴的單一代碼庫實現(xiàn)了簡易版ChatGPT。
只要你啟動一臺云GPU服務器,運行一個腳本,最快只要4小時,就能在類似ChatGPT的網(wǎng)頁界面與自己訓練的大語言模型對話。

整個項目約8000行代碼,可實現(xiàn)以下功能:
- 基于全新Rust語言實現(xiàn),訓練分詞器(tokenizer)
- 在FineWeb數(shù)據(jù)集上預訓練Transformer架構大語言模型,并通過多項指標評估CORE得分
- 在SmolTalk用戶-助手對話數(shù)據(jù)集、多項選擇題數(shù)據(jù)集、工具使用數(shù)據(jù)集上進行中期訓練(Midtrain)
- 執(zhí)行指令微調(SFT),并在世界知識多項選擇題數(shù)據(jù)集(ARC-E/C)、數(shù)學數(shù)據(jù)集(GSM8K)、代碼數(shù)據(jù)集(HumanEval)上評估對話模型性能
- 可選在GSM8K數(shù)據(jù)集上通過“GRPO”算法對模型進行強化學習(RL)訓練
- 在推理引擎中實現(xiàn)高效模型推理,支持KV緩存、簡易預填充/解碼流程、工具使用(輕量級沙箱環(huán)境中的Python解釋器),可通過CLI或類ChatGPT的WebUI與模型交互
- 生成單個Markdown格式報告卡,對整個訓練推理流程進行總結,并加入“游戲化”呈現(xiàn)(如用評分、進度等形式直觀展示結果)
整體成本只需約100美元(在8×H100上訓練4小時),就能訓練復刻出一個可進行基礎對話、創(chuàng)作故事詩歌、回答簡單問題的簡易版ChatGPT模型。

整體表現(xiàn)指標如下:

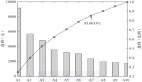
訓練約12小時后,模型在CORE指標上的表現(xiàn)即可超越GPT-2。
若進一步將成本提升至約1000美元(訓練約41.6小時),模型表現(xiàn)顯著提升,能解決簡單的數(shù)學/代碼問題,還能做多項選擇題。
舉個具體的例子:一個深度為30的模型訓練24小時后(相當于GPT-3 Small 125M的算力消耗,僅為GPT-3的千分之一),在MMLU數(shù)據(jù)集上可達到40多分,在ARC-Easy數(shù)據(jù)集上達70多分,在GSM8K數(shù)據(jù)集上達20多分。
卡帕西表示,他的目標是將這套完整的“強基線”技術棧整合為統(tǒng)一、極簡、易讀、可修改、易分發(fā)的代碼庫。
nanochat將成為LLM101n課程的壓軸項目(該課程仍在開發(fā)中)。
我認為它還有潛力發(fā)展為一個研究工具框架或基準測試的工具,就像之前的nanoGPT一樣。目前該項目遠未完全優(yōu)化(實際上存在大量可改進空間),但整體框架已足夠完整,可以發(fā)布到GitHub上,后續(xù)所有模塊都能在社區(qū)中進一步優(yōu)化。
等來新作的網(wǎng)友也已徹底瘋狂。項目剛發(fā)出來,GitHub Star數(shù)已飆到4.8k:

太酷了!跑一次這個項目,就把“機器學習工程師(ML Engineer)”放在我的簡歷上!

你發(fā)布的不只是代碼,更是可被理解的智慧,價值爆炸,栓Q。

在評論區(qū),卡帕西還解釋了nanochat基本架構與Llama類似,但更簡化一些,也借鑒了部分modded-nanoGPT的設計,整體是為此規(guī)模的模型找到一個穩(wěn)健的基礎架構。

以及這個項目基本上是完全手寫的。
我確實嘗試過用Claude或Codex之類的Agent來幫忙,但效果非常糟糕,幾乎毫無幫助。可能是因為這個repo的結構偏離了它們訓練數(shù)據(jù)的分布,所以它們根本“對不上號”。

話不多說,下面來看nanochat快速上手的詳細指南。
100美元成本,能捏出的最好的ChatGPT
從比如Lambda GPU Cloud上啟動了一臺8卡H100的服務器,每小時要花大約24美元,所以接下來得爭分奪秒了。
環(huán)境搭建
克隆項目:

目標是用100美元的成本訓練出一個最好的類ChatGPT模型,稱之為一次“速通(speedrun)”,可參考speedrun.sh這個腳本,它被設計成能在一臺全新的服務器上直接從頭到尾運行。
但接下來,卡帕西會逐步講解其中的每一步。
首先需要確保安裝了當下熱門的uv項目管理器。安裝uv,在.venv目錄下創(chuàng)建一個新的虛擬環(huán)境,獲取所有依賴項,然后激活該環(huán)境,這樣當輸入python時,使用的是虛擬環(huán)境中的Python,而不是系統(tǒng)自帶的Python:

接下來,需要安裝Rust/Cargo,以便編譯自定義的Rust分詞器。引入一個全新/自定義的分詞器確實有點折騰,但遺憾的是,卡帕西覺得早期minbpe項目中的Python版本速度太慢,而huggingface的分詞器又過于臃腫且令人困惑。
因此要專門為訓練打造了自己的新分詞器(經測試與Python版本效果一致),不過在推理時仍會使用OpenAI的tiktoken來保證效率。
現(xiàn)在就開始編譯分詞器吧:

訓練分詞器
接下來,需要獲取預訓練數(shù)據(jù),這樣才能:1)訓練分詞器;2)對模型進行預訓練。
預訓練數(shù)據(jù)就是大量網(wǎng)頁的文本內容,這里將使用FineWeb-EDU數(shù)據(jù)集。
通常來說,可以直接用huggingface datasets.load_dataset(),但卡帕西不喜歡它過于臃腫笨重且掩蓋了本應簡單的邏輯,所以把整個數(shù)據(jù)集重新打包成了簡單、完全打亂的分片,這樣就能輕松高效地隨意訪問,并且把它的sample-100B版本重新上傳為karpathy/fineweb-edu-100b-shuffle。
在這個頁面上,你還可以預覽數(shù)據(jù)集中的示例文本。每個分片是一個約0.25M個字符的簡單parquet文件,壓縮后(gzip格式)在磁盤上大約占100MB。總共有1822個分片,但訓練深度為20的模型只需要其中240個。
現(xiàn)在就開始下載所有數(shù)據(jù)吧。雖然需要下載約24GB,但在云服務器上通常速度很快:

默認情況下,所有這些都會被下載到~/.cache/nanochat目錄下。
下載完成后,開始訓練分詞器——它負責在字符串與符號碼本(codebook)序列之間進行雙向轉換。默認情況下,訓練的詞匯表大小是21?= 65,536個tokens(這是個不錯的數(shù)字),其中部分tokens會被保留作為特殊tokens(供后續(xù)聊天模式使用)。訓練集包含2B字符,訓練僅需約1分鐘。
訓練算法與OpenAI使用的完全一致(regex splitting, byte-level BPE)。想了解更多信息,可以看卡帕西關于tokenization技術的視頻講解。
訓練完成后可以評估這個分詞器:

評估結果顯示,實現(xiàn)了約4.8的壓縮比(即原始文本中平均4.8個字符壓縮為1個token),還可以看到與GPT-2、GPT-4分詞器的對比結果。
相比GPT-2(擁有50257個tokens),在壓縮文本方面全面更優(yōu),僅在數(shù)學內容上稍遜一籌:

與GPT-4相比,表現(xiàn)并不突出,但需要考慮到GPT-4擁有更大的詞匯表規(guī)模(100,277個tokens)。特別是在多語言處理方面GPT-4優(yōu)勢明顯(由于FineWeb數(shù)據(jù)集高度側重英語內容,這個結果很合理),同時在代碼和數(shù)學領域也更勝一籌:

盡管如此,即使在詞匯量較小的條件下,我們在FineWeb數(shù)據(jù)集上仍以微弱優(yōu)勢超越了GPT-4——因為這正是我們訓練所用的數(shù)據(jù)集,所以我們的分詞器能完美契合該文檔分布(例如在英語文本壓縮方面可能更具優(yōu)勢)。
預訓練
在啟動預訓練之前,需要下載另一個被卡帕西稱之為“評估包(eval bundle)”的文件。
在預訓練過程中,腳本會定期評估CORE指標。你可以在DCLM論文中看到一些細節(jié),本質上,它是一個很好的、標準化的、寬泛的指標,用于衡量模型在大量自動補全數(shù)據(jù)集上的表現(xiàn)好壞。
這些數(shù)據(jù)集包括HellaSwag、jeopardy、bigbench QA wikidata、ARC-Easy/Challenge、copa、commonsense qa、piqa、lambada、winograd、boolq等等(共22個)。
下載、解壓該評估包,并將評估包目錄放置到基礎目錄~/.cache/nanochat/eval_bundle下:

還建議(盡管這是可選的)再做一項設置:
配置wandb,以便在訓練過程中查看美觀的圖表。前面uv已經安裝好了wandb,但你仍需創(chuàng)建賬戶并登錄:

現(xiàn)在我們可以啟動預訓練了!這是計算量最大的部分,要訓練大語言模型(LLM),通過預測序列中的下一個token來壓縮互聯(lián)網(wǎng)網(wǎng)頁文本,在此過程中,大語言模型會獲取大量關于世界的知識:

在這里,通過scripts/base_train.py腳本在8塊GPU上啟動訓練。我們正在訓練一個有20層的Transformer。默認情況下,每塊GPU在每次前向/反向傳播時處理32行、每行2048個tokens的數(shù)據(jù),優(yōu)化器每一步總共處理32×2048=21?=524,288≈0.5M個tokens。
如果已經設置好了wandb,可以添加—run=speedrun(所有訓練腳本都支持該參數(shù))來設置運行名稱并記錄相關數(shù)據(jù)。
當你啟動訓練后,會看到類似這樣的輸出(為簡潔起見,省略了大量內容):

可以看到,這個Transformer有1280個channels,注意力機制中有10個注意力頭,每個頭的dim=128。它大約有560M參數(shù)。為了符合Chinchilla scaling law的建議,這意味著我們需要用560M×20≈11.2B tokens來進行訓練。
由于優(yōu)化器的每一步處理524,288個tokens,這意味著11.2B/0.5M≈21400次迭代。
通過對每個token的估計FLOPs與總tokens數(shù)相乘,我們可以知道這將是一個計算量達約4e19 FLOPs的模型。
學習率會自動按1/sqrt(dim)自動縮放,因為更大的模型更偏好更小的學習率。
我們使用Muon來優(yōu)化矩陣,使用AdamW來優(yōu)化嵌入和反嵌入。在這個模型中,沒有其他可訓練的參數(shù)(比如偏置、rmsnorm參數(shù)等)。訓練過程會定期報告“驗證集bpb”,即驗證數(shù)據(jù)集上每字節(jié)的位數(shù)。
每字節(jié)位數(shù)(bits per byte)是一個比典型的交叉熵損失更好的衡量指標,因為它通過每個token的字節(jié)數(shù)進一步歸一化了每個token的損失,使得該指標與分詞器無關。
所以,無論你使用的是詞匯量小的分詞器還是詞匯量大的分詞器,這個數(shù)值都是可比較的,而原始的交叉熵損失則不然。
注意,每一步大約耗時0.5秒,lrm是學習率衰減乘數(shù)(在訓練接近尾聲時,它會線性下降到0),報告的MFU(模型flops利用率)看起來很不錯,幾乎達到了一半,這意味著我們充分利用了可用的bfloat16計算能力。
現(xiàn)在,要等待大約3小時,直到4e19 FLOPs的計算量完成……在你的wandb圖表中,你應該會看到類似這樣的內容:

隨著時間的推移,bpb下降是好的跡象(說明模型能更準確地預測下一個token)。此外,CORE分數(shù)在上升。
除了這些近似的指標,還可以更全面地評估模型:

可以看到,訓練集/驗證集的bpb達到了約0.81,CORE指標上升到了0.22。
作為對比,評估包中包含了GPT-2模型的CORE分數(shù)。具體來說,0.22的CORE分數(shù)略高于GPT-2 large(0.21),但略低于GPT-2 xl(即“標準”的GPT-2,為0.26)。
此時,這個模型就像一個高級的自動補全工具,所以我們可以運行一些提示詞,來感受模型中存儲的知識。base_loss.py文件會運行這些提示詞。這些提示詞包括:

補全后的文本如下:

所以,模型知道巴黎是法國的首都、Au代表金、星期六在星期五之后、“冷”是“熱”的反義詞,甚至還知道太陽系的行星。
不過,它對天空的顏色還不太確定,也不太會做簡單的數(shù)學題。
對于一個花費72美元訓練出來的模型來說,已經不算太差了。推理過程使用了一個自定義的Engine class,利用KV緩存來實現(xiàn)高效推理,同時還簡單實現(xiàn)了兩種常見的推理階段:預填充和解碼。
我們的Engine class還支持工具使用(比如Python解釋器),這在GSM8K數(shù)據(jù)集上訓練時會很有用(之后會詳細介紹)。
訓練中期
接下來是中期訓練,這一步會在smol-SmolTalk數(shù)據(jù)集上進一步微調模型。
算法層面和預訓練完全一致,但數(shù)據(jù)集變成了對話內容,而且模型會去適應那些用于構建多輪對話結構的新特殊token。現(xiàn)在,每次對話大致是這樣的,大致遵循OpenAI的Harmony聊天格式:

像<|example|>這樣顯示的token是特殊token,遵循OpenAI特殊token的格式。中期訓練階段對模型的多種適配非常有用:
- 模型學習與多輪對話相關的特殊token(除了用于分隔文檔的<|bos|>token,基礎模型預訓練期間沒有這些token)。
- 模型適應對話的數(shù)據(jù)分布,而非互聯(lián)網(wǎng)文檔的數(shù)據(jù)分布。
- 對我們來說非常重要的一點是,必須教會模型做多項選擇題,因為在這么小的模型規(guī)模下,模型無法從隨機的互聯(lián)網(wǎng)數(shù)據(jù)中學會這一點。具體而言,模型必須學會將幾個選項與幾個字母(如ABCD)關聯(lián)起來,然后輸出正確選項的算法。通過混合10萬道來自MMLU輔助訓練集的多項選擇題來實現(xiàn)這一點。需要明確的是,問題不在于模型沒有相關知識,而在于它不理解多項選擇題的運作方式,無法將知識展現(xiàn)出來。這很重要,因為許多常見的模型評估(如MMLU)都采用多項選擇題的形式。
- 你可以教會模型使用各種工具。對我們來說,需要通過在特殊token <|python_start|>和<|python_end|>之間放入Python命令,來教會模型使用Python解釋器。這對之后解決GSM8K問題會很有用。
- 在中期訓練期間,你還可以針對許多其他適配進行訓練,例如上下文長度擴展(尚未探索)。
中期訓練混合數(shù)據(jù)默認是這樣的:

然后按如下方式啟動它:

這次運行只需要大約8分鐘,比預訓練的約3小時短得多。現(xiàn)在,模型已經是一個真正的聊天模型,能夠扮演助手的角色回答用戶的問題,可以對其進行評估:

得到了該階段模型的以下結果:

可以看到:
- 世界知識:前三項(ARC-E/C和MMLU)都是多項選擇題測試,用于衡量模型在各個領域的世界知識。由于有4個選項(A、B、C、D),隨機猜測的正確率約為25%,所以模型已經表現(xiàn)得比隨機猜測更好了。(對于這么小的模型來說,多項選擇題是相當難的)
- 數(shù)學:GSM8K是小學水平的數(shù)學題。這里的基準性能是0%,因為模型必須寫出實際的答案數(shù)字。目前我們的性能仍然不是很強,只解決了2%的問題。
- 代碼:HumanEval是一個Python編碼基準測試,同樣,隨機基準性能為0%。
- ChatCORE:這是卡帕西嘗試復制CORE分數(shù)對基礎模型的評估方式,并將其擴展到聊天模型的成果。也就是說,將上述所有指標都減去基準性能,這樣分數(shù)就在0到1之間(例如,隨機模型得0分,而不是MMLU上的25%),然后報告所有任務的平均值。它是對當前模型實力的一個單一數(shù)字總結。
- 這些評估仍然相當不完整,還有很多其他可以衡量但尚未衡量的方面。
確實沒有一個很好的圖表來展示這一步,但這里有一個之前對另一個更大的模型進行中期訓練的例子,只是為了讓你了解在微調運行期間這些指標上升時的樣子:

監(jiān)督微調
中期訓練之后是監(jiān)督微調(SFT)階段。
這是在對話數(shù)據(jù)上額外進行的一輪微調,理想情況下,你會精心挑選最優(yōu)質的好數(shù)據(jù),而且也會在這里進行安全訓練(比如助手拒絕不當請求的訓練)。
我們的模型甚至連天空的顏色都還不確定,所以目前在生物危害這類問題上可能還是安全的。這里會進行的一項領域適配是,SFT會拉伸數(shù)據(jù)行并對其進行填充,完全模擬測試時的格式。
換句話說,示例不再像預訓練/中期訓練時那樣為了訓練效率而被隨機拼接成長行。修正這種領域不匹配的問題,是另一個小小的“擰緊螺絲”式的提升。我們可以運行SFT并重新評估:

這個過程同樣只需運行約7分鐘,你應該能觀察到各項指標均有小幅提升:

終于,我們可以以用戶身份與模型對話了!
其實在中期訓練后就可以進行對話,但現(xiàn)在效果會更理想些。你可以通過終端窗口(方式1)或網(wǎng)頁界面(方式2)與它交流:

chat_web腳本會使用FastAPI來提供Engine服務。要確保正確訪問它,比如在Lambda上,使用你所在節(jié)點的公網(wǎng)IP,后面加上端口,例如http://209.20.xxx.xxx:8000/等等。
那看起來會很棒,大概是這樣的:

它短期內還無法在物理或詩歌比賽中獲勝,但話說回來——用這么少的預算能做到這個程度,看起來還是很酷的,而且這個項目還遠遠沒到充分調優(yōu)的地步。
強化學習
“速通”的最后一個階段是強化學習。
基于人類反饋的強化學習(RLHF)是一種不錯的方法,能提升幾個百分點的性能,還能緩解很多因采樣循環(huán)本身帶來的模型缺陷——比如幻覺、無限循環(huán)等。
但以我們的規(guī)模,這些都不是主要考慮因素。話雖如此,在我們目前使用的所有數(shù)據(jù)集中,GSM8K是唯一一個有清晰、客觀獎勵函數(shù)的(數(shù)學題的正確答案)。
所以我們可以運行RL(/GRPO)腳本,通過交替進行采樣和訓練的簡單強化學習循環(huán),直接在答案上進行性能攀升:

在強化學習過程中,模型會遍歷訓練集中所有的GSM8K題目,對完成情況進行采樣,然后我們會對這些采樣結果進行獎勵,并針對獲得高獎勵的樣本進行訓練。
我們使用的是高度簡化的GRPO訓練循環(huán),比如,不使用信任區(qū)域(舍棄參考模型和KL正則化),采用在策略(舍棄PPO的比率+裁剪),使用GAPO風格的歸一化(基于token級,而非序列級歸一化),優(yōu)勢函數(shù)僅通過均值進行簡單的獎勵平移(舍棄用除以標準差的z分數(shù)歸一化)。
所以最后得到的東西看起來更像是REINFORCE算法,但保留了GR(”組相對”)部分來計算獎勵的優(yōu)勢值。在當前規(guī)模和任務簡單度下,這種方法效果尚可。更多細節(jié)請參閱腳本。
目前強化學習默認是注釋掉的,因為它還沒有經過很好的調優(yōu),而且我們也沒有完整通用的RLHF。
只針對GSM8K進行了強化學習,這也是為什么用-a標志將評估也限制在GSM8K上。由于強化學習就像通過吸管汲取監(jiān)督信號,這個過程會運行相當長的時間。
例如,默認設置下運行約1.5小時后,效果如下所示:

成績
最后卡帕西指出的是項目文件夾里出現(xiàn)的report.md文件。它包含了很多與運行相關的細節(jié),最后還有一個不錯的總結表格:
- Characters:333,989
- Lines:8,304
- Files:44
- Tokens(approx):83,497
- Dependencies(uv.lock lines):2,004

總用時:3小時51分鐘
需要注意的是,由于目前對強化學習(RL)的支持還不太完善,在計算總耗時時把它排除了。到監(jiān)督微調(SFT)階段為止,整個過程運行了3小時51分鐘,總成本為(3+51/60)×24=92.4美元(如果加上強化學習,現(xiàn)在總時間會更接近5小時)。
甚至還剩下8美元可以買冰淇淋呢。
該你了
借助nanochat,你可以對任何部分進行調優(yōu)。
更換分詞器、修改任意數(shù)據(jù)、調整超參數(shù)、改進優(yōu)化過程……有很多想法可以去嘗試。你或許還想訓練更大的模型。這個代碼庫的設置能讓你輕松做到這一點。
只需使用—depth參數(shù)來更改層數(shù),其他所有相關設置都會基于這個參數(shù)作為復雜度的單一調節(jié)項而自動調整。比如,通道數(shù)會增加,學習率會相應調整等。
原則上,僅通過改變深度,你就能探索出一整套nanochat的“迷你系列”模型。使用更大的深度并等待更長時間,理論上你應該能得到明顯更好的結果。
你需要在base_train.py的預訓練階段傳入深度參數(shù)。例如,要得到一個CORE指標約為0.25、性能接近GPT-2的模型,嘗試depth=26是個不錯的選擇。
但訓練更大模型時,需要調整設備最大批處理大小,比如從32降至16:

代碼會察覺到這一變化并自動進行補償,它會通過2次梯度累積循環(huán)來達到目標批處理量0.5M。要訓練depth=30的模型,需要進一步降低設置:

依此類推。歡迎大家去閱讀代碼,卡帕西盡力讓代碼保持易讀性,添加了注釋,代碼整潔且易于理解。
當然,你也可以把所有內容打包,去詢問你喜歡的大語言模型,或者更簡單的是,使用Devin/Cognition的DeepWiki來對這個代碼倉庫提問。只需把代碼倉庫的URL從github.com改成deepwiki.com即可,比如 nanochat DeepWiki。
就是這樣,調優(yōu)整個流程的任意部分,重新運行,然后享受其中的樂趣吧!
AI界超高人氣專注于教育的大牛
卡帕西曾任特斯拉AI主管,之后去了OpenAI,去年2月從OpenAI離職。
他在整個AI界擁有超高的人氣,很大一部分來自于他的課程。
包括他自己的早期博客文字分享和后來的一系列Youtube視頻教程,他還與李飛飛合作開設的的斯坦福大學首個深度學習課程CS231n《卷積神經網(wǎng)絡與視覺識別》。

今天的不少學者和創(chuàng)業(yè)者,都是跟著他入門的。
卡帕西對教育的熱情,甚至可以追溯到學生時期在網(wǎng)上教大家玩魔方。

去年7月,從OpenAI離職的卡帕西突然官宣創(chuàng)業(yè),搞了一家AI原生的新型學校——Eureka Labs。
怎么理解AI原生?
想象一下與費曼一起學習高質量教材,費曼會在每一步中1對1指導你。
不幸的是,即使每個學科都能找到一位像費曼這樣的大師,他們也無法分身親自輔導地球上的80億人。
但AI可以,而且AI有無限的耐心,精通世界上所有的語言。
所以卡帕西要打造“教師+人工智能的共生”,可以在一個通用平臺上運行整個課程。
如果我們成功了,任何人都將易于學習任何東西,擴大教育這個概念本身的“范圍”和“程度”。
Eureka Labs首個產品,也是首門課程LLM101n。
手把手帶你構建一個類似ChatGPT的故事生成大模型,以及配套的Web應用程序。

GitHub repo:https://github.com/karpathy/nanochat
詳細指南:https://github.com/karpathy/nanochat/discussions/1