譯者 | 李睿
審校 | 重樓
隨著機器學習對訓練數據的需求與日俱增,傳統的集中式訓練方式在隱私要求、運營效率低下以及消費者日益增長的懷疑態度下不堪重負。由于道德和法律限制,醫療記錄或支付歷史等責任信息已經難以被簡單地集中采集與處理。
在此背景下,聯邦學習提供了一種截然不同的解決方案:它摒棄了“將數據傳輸至模型”的傳統思路,轉而采用“將模型推送至數據所在端”的創新模式。參與方基于自身數據在本地完成模型訓練,僅共享訓練所得的模型更新(如梯度或權重),而原始數據則始終保留于本地。
這種方式不僅從根本上保障了數據機密性,也使得原本因數據隔離而無法協作的各方能夠共建共享智能模型,在保護隱私的同時打破了“數據孤島”。
存在的問題
集中式數據管道雖然推動了人工智能的許多重大進步,但這種方法也存在著重大風險:
?隱私泄露:歐盟《通用數據保護條例》(GDPR)、美國《健康保險流通與責任法案》(HIPAA)以及印度的《數字個人數據保護法案》(DPDP)等法規對數據的收集、存儲和傳輸設置了嚴格的限制。
?運行效率低下:在網絡之間復制TB規模的數據既耗時又昂貴。
?基礎設施成本高昂:存儲、保護和處理龐大的集中式數據集需要成本昂貴的基礎設施,對規模較小的組織構成沉重負擔。
?偏見放大:集中式數據集會過度代表某些特定群體或機構的特征,導致基于此類數據訓練的模型在廣泛現實場景中的泛化能力下降。
上述問題使得集中式訓練在多數實際應用場景中難以有效推行。
新范例:聯邦學習
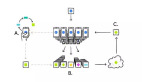
聯邦學習(FL)顛覆了傳統流程。它不是將原始數據集中到一個中心點,而是將模型安裝到每個客戶端(設備、醫院或機構)。在本地進行訓練,只將產生的模型更新內容(如權重或梯度)傳輸回中心。
聯邦學習從根本上顛覆了傳統的數據處理流程。它不再將原始數據匯集至中央服務器,而是將模型部署于每個客戶端(例如設備、醫院或機構)。客戶端利用本地數據完成訓練,僅將產生的模型更新(例如權重或梯度)回傳至中央服務器進行聚合。
下圖展示了聯邦學習的工作流程:客戶端在本地訓練模型,并將更新結果發送至中央服務器;中央服務器將這些更新內容整合為一個全局模型。

谷歌公司在2016年率先應用這一技術,在無需收集用戶擊鍵數據的前提下,成功提升了Gboard輸入法的下一個單詞預測能力。鍵盤在設備端進行本地學習,只上傳模型更新,由系統整合為統一的全局模型。最終,谷歌在不損害任何用戶輸入隱私的情況下,持續優化了數百萬設備的預測準確性。

這一突破使得聯邦學習受到關注。谷歌公司在2016年發表的論文中使用的聯邦平均(FedAvg)算法構成了大多數現代聯邦學習系統的核心。到2018年,研究人員通過壓縮技術和安全聚合解決了通信開銷和隱私問題。從2019年開始,聯邦學習進入醫療、金融和制藥等敏感領域,這些領域的合作基于嚴格的數據隱私。
通過讓敏感信息始終保留在本地,聯邦學習將這一理念的應用范圍從移動鍵盤延伸至更廣闊的領域,使得以往相互隔離的“數據孤島”得以實現協同智能,從而在不犧牲隱私的前提下開辟了新的可能性。
隱私優先
聯邦學習在設計之初便將隱私保護作為其核心原則:原始數據無需離開本地,其訓練過程均在終端設備或機構內部服務器上完成。這一架構使其符合GDPR、HIPAA等數據法規的嚴格要求,使組織能夠在合規前提下持續推動技術創新。
更重要的是,聯邦學習成功釋放了諸如醫療記錄、銀行交易歷史等敏感數據的潛力——這些信息曾因隱私與合規顧慮而長期分散孤立。與此同時,該系統具備卓越的可擴展性,能夠實時協調數百萬臺設備同步參與訓練。
在安全層面,聯邦學習憑借其分布式數據存儲特性,顯著降低了系統性風險:單一節點的安全漏洞不會導致整個數據庫遭受威脅。此外,該技術還在保障隱私的同時實現了高效的個性化:本地模型持續學習用戶特定行為(如鍵盤輸入習慣與語音特征),而聚合后的全局模型則不斷迭代優化,使所有用戶共同受益。
一個值得關注的案例研究是醫療領域:多家醫院使用聯邦學習來預測敗血癥風險。每家醫院都在本地進行學習,并只交換匿名化處理的信息,這使得這些醫院的預測性能都得到了提高,并且遵循了患者隱私與合規要求(Rodolfo,2022)。
由于數據保留在本地,僅共享模型更新仍可能隱含敏感模式泄露的風險。差分隱私(DP)被引入作為有效補充,通過在更新中注入可控噪聲,使得網絡攻擊者難以通過更新獲得用戶信息。
安全多方計算(SMPC)和同態加密(HE)在聚合時以一種任何人(甚至是服務器)無法知道原始貢獻的方式保護更新。
此外,聯邦學習仍面臨對抗性攻擊風險擊的挑戰:例如模型中毒允許注入惡意更新,推理攻擊可能試圖獲取機密信息。目前防御方法包括:強大的聚合規則、異常檢測以及能夠在安全性和模型實用性之間取得平衡的隱私保護方法。
聯邦學習的類型
聯邦學習并不是“一刀切”的方案。其架構需根據機構的數據分布特點調整。有時,不同組織收集不同用戶群體的相似信息;有時收集相似用戶群體的不同信息;有時甚至是用戶和特征部分重疊的信息。針對這些場景,聯邦學習被具體分為三類:橫向聯邦學習、縱向聯邦學習、聯邦遷移學習。

橫向聯邦學習
橫向聯邦學習是指在多個組織間開展協作學習的一種模式,其特點是各參與方數據特征空間相同,但覆蓋的用戶群體不同。例如,不同醫院可能擁有結構相同的患者信息(如年齡、血壓、血糖水平等),但這些數據來源于不同的患者群體。在該模式下,各方僅在本地進行模型訓練,只上傳模型參數更新(而不是原始數據),從而在無需共享數據的前提下,共同構建更優的全局模型,通過這種方式可以有效提升模型的泛化能力(Jose, 2024)。
垂直聯邦學習
在縱向聯邦學習中,多個組織擁有同一批客戶群體,但各自掌握不同的特征數據。例如,銀行可能持有客戶的資金流水記錄,而電子商務公司則擁有同一批用戶的購物歷史。雙方可通過加密信道安全地整合這些互補的數據特征,在不泄露原始數據的情況下訓練聯邦共享的模型。該機制為欺詐檢測、風險評估與信用評分等場景提供了高效且合規的解決方案(Abdullah, 2025)。
聯邦遷移學習
聯邦遷移學習則適用于各方數據主體重疊度較低、特征交集極少的場景。例如,一家機構可能擁有醫學影像數據,而另一家機構則掌握不同患者群體的實驗室數據。即使在這樣的數據異構條件下,聯邦遷移學習仍能借助聯邦模型更新,安全地遷移已經學習到的特征表示,從而在不共享原始數據的前提下實現跨機構協作。
WeiGuo(2024)指出,其所提出的方法進一步將聯邦學習推廣至地理分散、數據高度異構的環境中,顯著增強了跨行業、跨研究領域的隱私保護協作能力。
聯邦學習的工作原理
聯邦學習是一種分布式機器學習模式,多個客戶端(例如電話、醫院或公司)利用本地數據訓練模型。原始數據不會上傳到某個中間人服務器,而上傳的是模型更新內容。
步驟1:客戶端選擇和模型初始化
中間人服務器初始化全局模型,并選擇符合條件的客戶端(在線狀態、空閑狀態、數據量是否充足)。
步驟2:本地訓練
被選中的客戶端使用本地數據,通過小批量隨機梯度下降等常用算法對接收到的全局模型進行訓練。

可選的隱私保護措施:安全飛地(基于硬件的保護)或差分隱私(添加噪聲)。
步驟3:模型更新共享
客戶端不發送原始數據;與其相反,它們會發送參數更新(梯度/權重)。這些更新內容可以通過安全聚合進行加密或屏蔽。
步驟4:聯邦平均(FedAvg)
服務器使用聯邦平均(FedAvg)聚合客戶端更新:

其中Nk是客戶端k的數據集的大小。
異步或分層聚合可用于大規模部署以提高效率。
步驟5:全局模型分發和迭代
新生成的全局模型會被重新分發以進行另一輪訓練。迭代會持續進行,直到模型收斂或達到性能目標。
實際應用示例
谷歌的“Hey Google”語音查詢功能使用了聯邦學習,使得語音數據在每部手機上進行本地處理。手機只傳輸模型更新內容,而不是聲音片段,從而確保了在不犧牲隱私的情況下保證更好的模型(Jianyu, 2021)。
核心技術組件
聯邦學習使得多個分散的客戶端能夠在不共享原始數據的情況下協作學習機器學習模型。分布式模型依賴于多個管理計算、通信、聚合和安全的技術組件。由于這些組成部分之間的協同作用,聯邦學習的范式具有可擴展性、高效性和隱私保護性。
1.聯邦平均(FedAvg)
聯邦平均(FedAvg)是聯邦學習的核心。在該模型中,每個客戶端都根據自己的數據在本地訓練模型,并將參數更新發送到中央服務器,而不是模型本身。服務器將這些更新(最常見的是通過平均)整合到全局模型中。這個過程在訓練中反復迭代,直到收斂。
以下摘錄提到了基本步驟:在客戶端數據上進行本地訓練,獨立地將更新內容(而不是原始數據)傳輸到服務器,以及服務器對更新進行平均以提高全局模型的準確性。
Python
global_model = initialize_model()
for round in range(num_rounds):
client_weights = []
client_sizes = []
# Each client trains locally
for client in clients:
local_model = copy(global_model)
local_data = client.get_data()
# Local training (e.g., a few epochs of SGD)
local_model.train(local_data)
# Collect weights and data size
client_weights.append(local_model.get_weights())
client_sizes.append(len(local_data))
# Weighted average aggregation
total_size = sum(client_sizes)
avg_weights = sum((size/total_size) * weights
for size, weights in zip(client_sizes, client_weights))
# Update global model
global_model.set_weights(avg_weights)
print(f"Completed round {round+1}, global model updated.")2.同步機制
有兩種方法可以對模型更新內容進行同步:
- 同步訓練:服務器保持空閑狀態,直到所有客戶機完成更新并取其平均值。它提供了一致性,但可能會因運行較慢的設備增加延遲(“滯后節點問題”)。
- 異步訓練:服務器會在收到更新內容時立即進行更新,從而更快地完成工作,但偶爾會使用稍微過時的參數。
3.客戶端設備
客戶端是聯邦學習的基石。它們可能是智能手機、物聯網設備或大型企業服務器。每個客戶端在本地使用私有數據訓練模型,并只共享更新內容,這有助于保護隱私,同時還捕獲參與者之間非獨立同分布(non-IID)數據集的多樣性。
4.中央服務器(聚合器)
聚合器負責處理訓練工作。它提供初始的全局模型,收集客戶端的更新內容,將其整合,并重新分發改進后的模型。它還必須應對現實世界中的挑戰,例如客戶流失、硬件能力的變化和參與水平的不平衡。
5.通信效率
由于聯邦學習在大多數情況下是在帶寬受限的設備和網絡上運行的,因此必須最小化通信開銷。模型壓縮、稀疏化和量化等方法可以在不犧牲模型性能的情況下顯著降低數據傳輸成本。
6.處理異構性
客戶端設備在數據分布、計算和網絡穩定性方面具有高度的異構性。為了解決這個問題,個性化聯邦學習和FedProx優化等方法使模型能夠在動態條件下表現良好,從而促進公平性和魯棒性。
7.容錯性和魯棒性
最后,聯邦學習系統對失敗甚至主動的惡意嘗試具有彈性。客戶端采樣、退出處理、異常檢測和信譽評估等技術即使在動蕩的環境中也能確保可靠性。
效率優化技術
聯邦學習通過壓縮模型更新的方法將通信成本降至最低。稀疏化、量化和壓縮在不犧牲模型精度的情況下減少了數據大小,從而使得即使在低帶寬設備上也可以進行訓練。
壓縮技術
壓縮方法通過減少冗余信息的表示以最小化客戶端和服務器之間傳輸的模型更新內容的大小。例如,預測編碼消除了模型梯度中的冗余,在不影響學習性能的情況下大幅降低了通信成本。

量化
量化通過使用更低精度的數值(例如將32位浮點數轉換為8位整數)來表示模型權重或梯度,從而減少通信開銷。近年來的研究引入了誤差補償機制,以最大限度地減少精度損失,使量化成為帶寬受限聯邦系統的可行解決方案。
稀疏化
稀疏化通過僅傳輸對模型性能有關鍵影響的梯度更新,同時舍棄貢獻微小的部分,以此降低通信負載。在實際應用中,這種方法能大幅減少傳輸數據量,如果與量化技術結合,則可實現更高的壓縮比。
構建隱私優先的未來
聯邦學習不僅是一種在沒有原始數據的情況下訓練模型的方法,也是人工智能系統中數據、協作和信任管理的重新定義。
數據主權
通過保留原始數據或機器的信息,聯邦學習可以滿足GDPR和HIPAA等高度嚴格的隱私法規,并且可以在不公開敏感數據的情況下實現跨國協作。
英偉達公司與倫敦國王學院、Owkin公司合作,使用聯邦學習在多家醫院訓練腦腫瘤分割模型。各個機構都在從BraTS 2018數據集中獲取的磁共振成像(MRI)掃描上進行本地訓練,并只共享匿名化更新內容,并通過差分隱私技術增強隱私保護。最終,聯邦學習方案的準確率與中心化訓練相當,且患者信息全程未離開醫院服務器。這清晰地表明了聯邦學習在醫學領域的可行性(英偉達與倫敦國王學院,2019年)。
人工智能民主化
聯邦學習使得小型機構與邊緣設備能夠通過共享模型更新(而非數據)來參與協作訓練。谷歌Gboard等案例表明,聯邦學習能夠優化數百萬設備的系統性能,而無需集中任何數據。
魯棒性和安全性
聯邦學習通過引入安全聚合和差分隱私等技術來增強保護。這確保了即使是由設備發送的微小模型更改也不能被反編譯。也就是說,黑客甚至中央服務器都無法使用共享參數拼湊敏感的本地數據。
更公平的代表性
聯邦學習基于各種分散的數據進行訓練,從而最大限度地減少了在小規模集中數據上進行訓練時可能出現的偏差。這提高了模型在不同人群中的代表性,增強了醫療、金融服務和教育等領域的公平性。
結論
聯邦學習有力地證明,隱私保護與模型性能無需以犧牲對方為代價。通過將數據保留在源頭,同時實現協同智能,聯邦學習解決了人工智能面臨的一些核心挑戰:合規性、信任、公平性和安全性。從數百萬臺智能手機優化預測輸入法,到協助多家醫院改善患者治療效果,這項技術已經在重塑智能系統的構建方式。
人工智能的未來不再是以犧牲隱私為代價,而是在其背后構建智能系統。聯邦學習不僅僅是一項技術方案,更是引領人們邁向更安全、更民主、更具代表性的人工智能未來的路線圖。
原文標題:Federated Learning: Training Models Without Sharing Raw Data,作者:Saisuman Singamsetty