













召喚100多位學(xué)者打分,斯坦福新研究:「AI科學(xué)家」創(chuàng)新確實強(qiáng)
近日,一篇關(guān)于自動化 AI 研究的論文引爆了社交網(wǎng)絡(luò),原因是該論文得出了一個讓很多人都倍感驚訝的結(jié)論:LLM 生成的想法比專家級人類研究者給出的想法更加新穎!
我們都知道通過調(diào)節(jié) LLM 的溫度值確實可以調(diào)整它們的隨機(jī)性和創(chuàng)造性,但在科學(xué)研究方面比人類還懂創(chuàng)新?這還是超乎了很多人的想象 —— 至少很多人沒想到這會來得這么快。難道 AI 科學(xué)家真的要來了?

那么,這項來自斯坦福大學(xué)的研究究竟得出了什么樣的結(jié)論呢?

- 論文地址:https://arxiv.org/abs/2409.04109
- 調(diào)查鏈接:https://tinyurl.com/execution-study
- 項目地址:https://github.com/NoviScl/AI-Researcher
LLM 能生成新穎的研究思路嗎?
為了準(zhǔn)確地對比 LLM 與人類在科研思路創(chuàng)新方面的能力,斯坦福大學(xué)的這個研究團(tuán)隊招募了 104 位 NLP 研究者,讓其中 49 位寫下創(chuàng)新研究想法,然后再讓 79 位專家對 LLM 和人類給出的思路進(jìn)行盲測。請注意,其中有 24 位人類專家既寫了想法,也參與了盲測,當(dāng)然他們并不評估自己寫的內(nèi)容。
模型(或者按該團(tuán)隊的說法:思路生成智能體)方面,該團(tuán)隊使用了 claude-3-5-sonnet-20240620 作為骨干模型。具體來說,給定一個研究主題(比如:可以提升 LLM 事實性并降低其幻覺的提示方法),讓 LLM 生成一系列對 Semantic Scholar API 的函數(shù)調(diào)用。這個論文檢索動作空間包括 {KeywordQuery (keywords), PaperQuery (paperId), GetReferences (paperId)} 。每個動作生成都基于之前的動作和已執(zhí)行的結(jié)果。
該研究使用的研究主題有 7 個:偏見、編程、安全性、多語言、事實性、數(shù)學(xué)和不確定性。下表是各個主題的想法數(shù)量:

研究過程如下圖所示:

這里我們不細(xì)說其詳細(xì)的設(shè)置和評估過程,詳見原論文。總結(jié)起來就是比較人類專家與 AI 智能體生成的科研思路的新穎程度。我們直接來看結(jié)論。
根據(jù)該團(tuán)隊思路評分(Idea Ranking)規(guī)則,他們對人類和 AI 提出科研思路進(jìn)行了打分,見圖 2 和表 7:
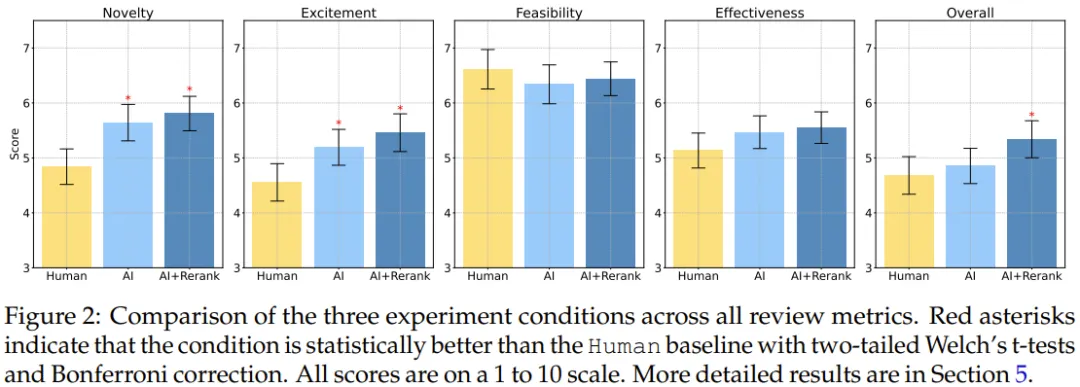
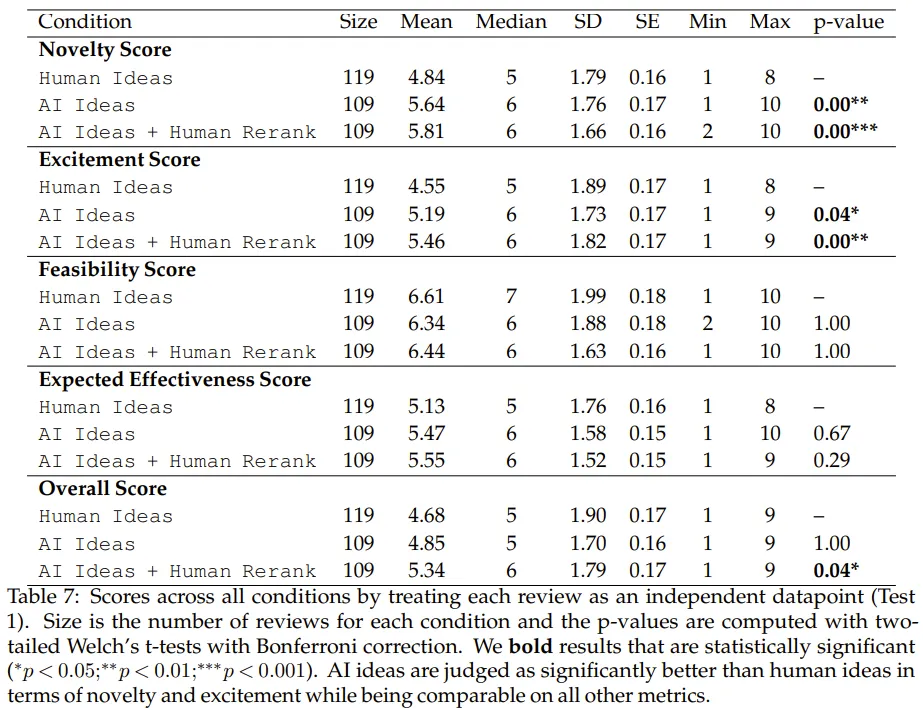
其中 Human Ideas 是指招募的專家研究者提出的思路,而 AI Ideas 則是 LLM 智能體給出的排名第一的思路。AI Ideas + Human Rerank 是指由 AI 生成思路但由本研究一作 Chenglei Si 手動從排名靠前的思路中選擇他認(rèn)為最好的一個。
可以看到,在新穎度方面,不管是 AI Ideas 還是 AI+Rerank,都顯著優(yōu)于 Human Ideas(p < 0.01)。在激動人心(excitement)分?jǐn)?shù)上,AI 生成的思路的優(yōu)勢更是明顯(p<0.05)。并且 AI Ideas + Human Rerank 的整體分?jǐn)?shù)也優(yōu)于人類(p<0.05)。不過 AI 生成的思路在另外兩方面(可行性和有效性)與人類的差別不大。
當(dāng)然,我們也能看出,這項調(diào)查研究有一些明顯的局限,比如其調(diào)查范圍較小,樣本量太少了,評價很主觀。另外作者也指出人類研究者可能會「藏私」,可能并不會分享自己的最佳想法。
不管怎樣,這項研究證明了一點:讓 AI 參與到科學(xué)研究中多半是有利的。尤其是當(dāng)你靈感枯竭、思維阻塞時,問一問 LLM 或許就能有意想不到的收獲。
生成創(chuàng)新想法的 AI 工具,正在不斷涌現(xiàn)
實際上,已經(jīng)有研究團(tuán)隊在打造專用于此類任務(wù)的 AI 工具了。比如近日一位專注于開發(fā) LLM 應(yīng)用的研究者 Shubham Saboo 就在社交網(wǎng)絡(luò)分享了使用 Cursor 構(gòu)建一個多智能體 AI 研究者的過程。他表示整個過程用時不到 5 分鐘!參見如下視頻:

也有人分享了自己的一項相關(guān)研究,表示可以使用 LLM 和因果圖譜自動生成心理學(xué)假設(shè),并生成比 GPT-4 和博士生表現(xiàn)都好:
近日,印度科學(xué)學(xué)院(Indian Institute of Science,IISc)的研究者發(fā)現(xiàn),AI 在設(shè)計創(chuàng)意方面也比人類更有想法。具體來說,AI 可通過一種新的人工智能會話式「主動構(gòu)思」(Active Ideation)界面來生成新創(chuàng)意。作為一種創(chuàng)意構(gòu)思生成工具,它可幫助新手設(shè)計師緩解一部分的初始延遲和構(gòu)思瓶頸。

- 論文標(biāo)題:A Novel Idea Generation Tool using a Structured Conversational AI (CAI) System
- 論文地址:https://arxiv.org/pdf/2409.05747
具體來說,這是一種動態(tài)、交互、上下文響應(yīng)式方法,通過大型語言模型(LLM)主動參與,為不同的設(shè)計問題生成多個潛在創(chuàng)意陳述。論文稱之為「主動構(gòu)思場景」,它有助于促進(jìn)基于對話的持續(xù)互動、對上下文敏感的對話以及多產(chǎn)的構(gòu)思生成。
在當(dāng)前的很多研究設(shè)計中,從書面信息到基于關(guān)鍵詞的在線資源檢索的轉(zhuǎn)變至關(guān)重要。這強(qiáng)調(diào)了文本在轉(zhuǎn)變思維模式和通過發(fā)展高級設(shè)計語言促進(jìn)系統(tǒng)化構(gòu)思方面的重要性。下表 1 總結(jié)了最常用的傳統(tǒng)構(gòu)思技術(shù)、其過程、局限性、涉及的認(rèn)知原則以及在產(chǎn)生創(chuàng)意方面的預(yù)期結(jié)果。

雖然這些傳統(tǒng)方法已被廣泛使用,但它們往往無法為新手設(shè)計師提供積極的支持。在產(chǎn)生新穎想法的過程中,原創(chuàng)性和多樣性主要依賴于設(shè)計者。這一空白標(biāo)志著將人工智能與構(gòu)思相結(jié)合的潛力。
這篇論文就深入探討了對話式人工智能(CAI)系統(tǒng)的設(shè)計、開發(fā)和潛在使用案例,重點是比較基于 CAI 的構(gòu)思工具與傳統(tǒng)方法的效率。
有兩個有趣的特點使 CAI 系統(tǒng)看起來很智能:(a) 能夠就給定主題生成智力上可接受的文章,(b) 能夠在先前交互的基礎(chǔ)上生成對后續(xù)詢問的回復(fù)。這使得交互成為關(guān)于特定主題的連貫對話。因此,如果特征(a)是對一個觀點的描述,那么特征(b)就可以被構(gòu)建為對該觀點的闡述和澄清。
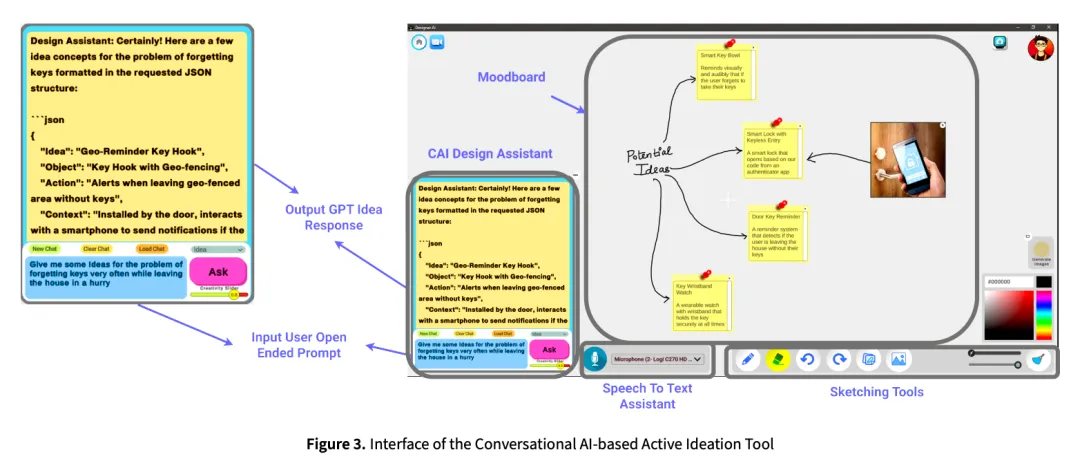
如圖 3 所示,這項研究設(shè)計并開發(fā)了一個主動構(gòu)思界面,使用了生成式預(yù)訓(xùn)練 Transformer(GPT)對話式人工智能系統(tǒng),該系統(tǒng)嵌入了一個交互式情緒板(moodboard)。GPT 為自然語言交互提供了基礎(chǔ),使其能夠根據(jù)用戶輸入做出響應(yīng)并生成創(chuàng)意陳述,情緒板提供了一種快速記錄這些想法的手段。因此,該界面為設(shè)計師提供了一個對話式的直觀平臺,由 GPT 驅(qū)動創(chuàng)意生成。
由于本研究調(diào)查的是建議的基于 CAI 的構(gòu)思界面對新手設(shè)計師的潛在益處,因此招募了 30 名產(chǎn)品設(shè)計研究生(下圖),分為 A 和 B 兩組。

論文對這 30 名新手設(shè)計師進(jìn)行了試點研究,讓他們使用傳統(tǒng)方法和基于 CAI 的新界面,針對給定問題產(chǎn)生創(chuàng)意。然后,讓專家小組使用流暢性、新穎性和多樣性等關(guān)鍵參數(shù)對結(jié)果進(jìn)行了定性比較。
研究結(jié)果表明,本文所提出的 AI 工具在生成多產(chǎn)、多樣和新穎的想法方面非常有效。通過在每個構(gòu)思階段加入提示設(shè)計的結(jié)構(gòu)化對話風(fēng)格,使界面更加統(tǒng)一,更方便設(shè)計者使用。結(jié)果發(fā)現(xiàn),這種結(jié)構(gòu)化 CAI 界面所產(chǎn)生的反應(yīng)更加簡潔,并與隨后的設(shè)計階段(即構(gòu)思階段)保持一致。

從圖 5(a)中可以看出,68% 的專家認(rèn)為 GPT 產(chǎn)生的想法更有意義。此外,圖 5 (b) 顯示,GPT 生成的語句的得票率始終高于設(shè)計者生成的想法。
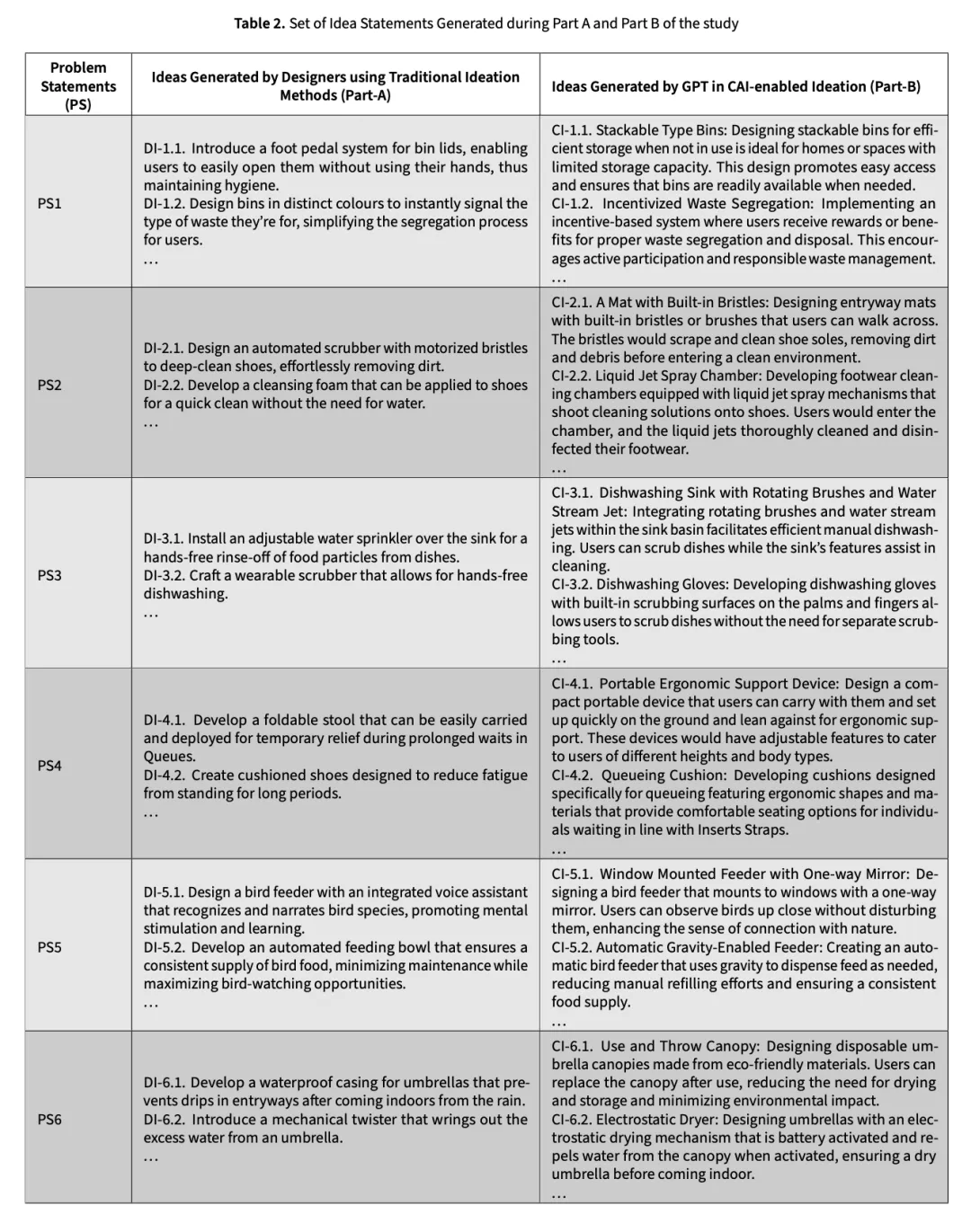
下表是 A 和 B 兩組的想法陳述對比:
以下是不同維度下,人類與 GPT 構(gòu)思的評估結(jié)果對比:


更多研究細(xì)節(jié),可查看原論文。
結(jié)語
創(chuàng)新,長久以來被視為人類不可被機(jī)器觸及的領(lǐng)地,然而,LLM 所展現(xiàn)的「幻覺」現(xiàn)象卻悄然打開了這扇門,揭示了創(chuàng)新機(jī)制可能并非我們想象中那般高不可攀。
近期在 AI 創(chuàng)造性研究領(lǐng)域的突破,預(yù)示著 AI 在創(chuàng)意之路上或?qū)⒂瓉砬八从械膹V闊天地。展望未來,或許在不遠(yuǎn)的將來,我們將見證 AI 科學(xué)家、AI 導(dǎo)演、AI 設(shè)計師們紛紛揮灑創(chuàng)意,它們的作品將點亮 AI 應(yīng)用的嶄新篇章。
























